# Technische Beschreibung
# Architektur
# Elasticsearch
Die Elasticsearch ist eine verteilte, hoch skalierbare Open-Source-Such-Engine auf Basis von Apache Lucene. Mit der Elasticsearch ist es möglich, große Datenmengen zu speichern und extrem schnell zu durchsuchen. Die Kommunikation erfolgt dabei über ein RESTful Webinterface.
Durch die große Verbreitung können Sie im Internet viele Grundlagendokumente und Vorgehensweisen finden. In dieser Dokumentation werden deshalb lediglich die Details herausgearbeitet, die relevant für den Einsatz im ELO Systemumfeld sind. Für Informationen darüber hinaus empfehlen wir folgenden Einstiegspunkt für weitere Recherchen: https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html (opens new window).
# Lucene
Die Elasticsearch nutzt Apache Lucene als core library. Mit der Elasticsearch kann jeder Index in mehrere Stücke (sogenannte Shards) aufgeteilt werden. Ein Shard entspricht einem Lucene-Index. Dieser besteht physikalisch aus einem Ordner mit den zugehörigen Index-Dateien.
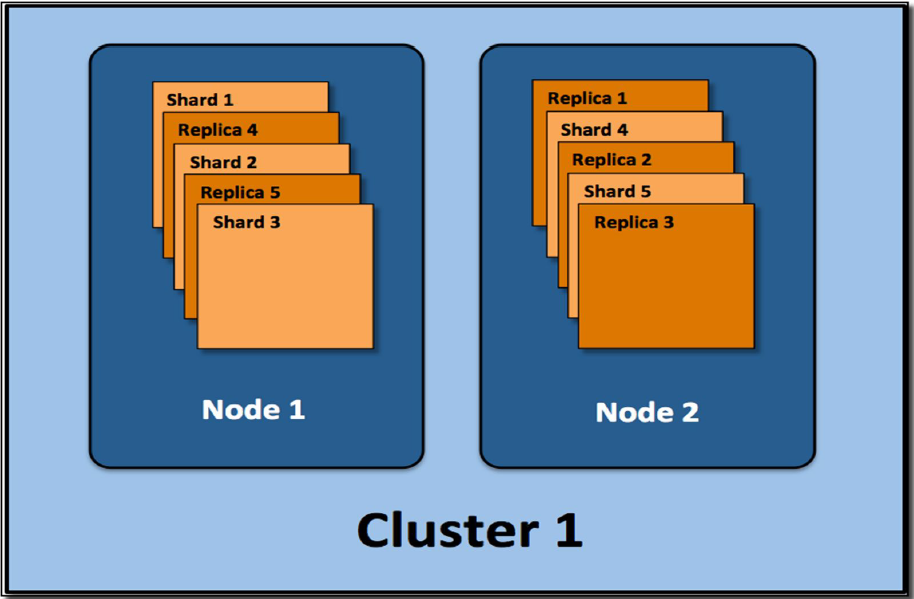
Die Shards können auf mehrere Server (Nodes) aufgeteilt werden. Es können Replicas gebildet werden. Dies ergibt dann einen Cluster.
# Sprachunterstützung
Die Elasticsearch verwendet sowohl bei der Indexierung als auch bei der Suche eigene Sprach-Analyzer. Dadurch werden sprachspezifische Suchregeln und -muster optimiert. Bei den ELO Spezifika müssen Sie daher beachten, dass die Repository-Sprache (Auswahl bei der Installation) einen maßgeblichen Einfluss auf die Suche besitzt.
Folgende Sprachen werden unterstützt:
Deutsch, Englisch, Französisch, Spanisch, Italienisch, Portugiesisch, Dänisch, Schwedisch, Polnisch, Niederländisch, Tschechisch, Ungarisch, Rumänisch, Türkisch, Bulgarisch, Finnisch, Griechisch, Norwegisch, Russisch.
# Verarbeitung mit ELO
Die Verarbeitung mit ELO können Sie dem folgenden vereinfachten Schema entnehmen:

Der ELO Indexserver übergibt die Daten an die Elasticsearch, die bei der Indexierung (und auch bei der Suche) eigene Sprach-Analyzer verwendet. Die Indexdaten werden in Lucene-Indexen gespeichert.
Für das Suchen im Index wird also der Zugriff auf:
- die Index-Dateien,
- eine konsistente Lucene-Datenbank,
- ein funktionsfähiger Elasticsearch-Sprach-Analyzer,
- ein laufender ELO Indexserver (ELOix)
vorausgesetzt.
# Sicherheit
Seit der ELO ECM Suite 10.2 erfolgt die Kommunikation zwischen dem ELO Indexserver (ELOix) und der Elasticsearch verschlüsselt (SSL). Dazu wird das Search Guard Plugin verwendet.
# Installation und Upgrade
# ELO Server Setup
Die Installation oder ein Upgrade erfolgt über das ELO Server Setup. Dieses erzeugt – falls noch nicht vorhanden – die Konfigurationen, installiert das Elasticsearch-Programm und den Dienst, sowie ein Datenverzeichnis, in dem die Indexdaten abgelegt werden. Folgende Optionen können im ELO Server Setup gesetzt werden:
- Name des Dienstes
- Memory-Wert
- Port
- Datenverzeichnis

- Mit ELOenterprise auch weitere Elasticsearch-Server (siehe dazu auch Lizenzbestimmungen bei der Verteilung von Serverprozessen).
Beachten Sie
Ab ELO 21.2 wird der Port der ELO iSearch (Standard: 9200) mit TLS/SSL gesichert.
Bei Aufruf über einen Browser wird beim ersten Zugriff ggf. eine Zertifikatswarnung angezeigt.
Je nach verwendetem Browser und Betriebssystem müssen Sie das angebotene Zertifikat entweder in den Zertifikatsspeicher des Browsers oder in den Zertifikatsspeicher des Betriebssystems übernehmen. Beispielsweise laden Sie bei Verwendung von Microsoft Edge oder Google Chrome unter Microsoft Windows die Datei keystore.jks aus <ELO>\config\elastic\<Server ELO iSearch>\certificates in den Windows-Zertifikatsspeicher. Bei Verwendung von Mozilla Firefox nehmen Sie das Zertifikat durch Bestätigen der Warnmeldung in den Zertifikatsspeicher von Firefox auf.
# Prüfungen nach der Installation
Nach der Installation können Sie zur Überprüfung mit administrativem Tomcat-Konto https://<server>:<port> (Standard-Port ist 9200) aufrufen. Bei Verwendung eines beliebigen Browsers wird eine JSON-Datei ausgegeben, die Sie in einem Editor öffnen können.
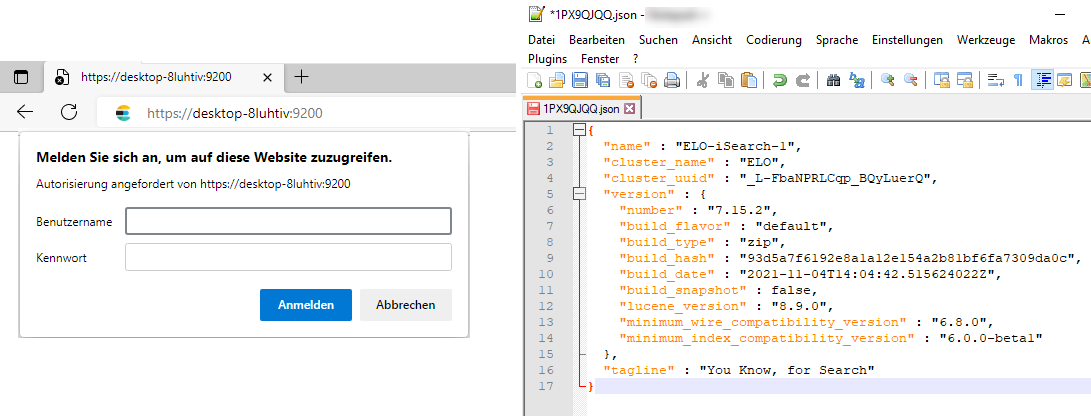
Dadurch können Sie sich wichtige Basisdaten wie Version und Namen anzeigen lassen.
Über die ELO iSearch Configuration können Sie weitere Prüfungen vornehmen. Sie erreichen die Konfiguration über die Indexserver-Konfigurationsseite oder über folgenden Link (Anmeldung mit administrativem Tomcat-Konto):
https://<server>:<ixport>/ix-<REPOSITORY>/manager/esconfig/#/iSearchConfig
# Indexaufbau nach Upgrade von älteren ELO Versionen
Nach einem Upgrade einer früheren ELO Version (bis einschließlich ELO Version 23.6) auf ELO Version 25.0 oder später ist ein Neuaufbau (Re-Index) der Indexdaten erforderlich. Das ELO Server Setup entfernt die bisherigen Elasticsearch-Indexe, da diese mit der aktuellen Elasticsearch-Version nicht mehr kompatibel sind.
Bei der Re-Indexierung wird zunächst der vorhandene Index gelöscht und dann neu aufgebaut. Alle Felder werden sowohl tokenized (in Token aufgeteilt) als auch not tokenized (als Phrase) abgespeichert, sodass eine Änderung an dieser Feld-Einstellung keinen Re-Index erfordert. Zusätzlich werden aus den durch den ELO Volltext-Prozess entstandenen FT*.txt-Dateien die Volltextinhalte ausgelesen und für die Indexierung verwendet.
Ein Re-Index wird über die ELO iSearch-Konfiguration im Tab Indexer angestoßen.
Der Fortschritt wird nach einem Refresh der Seite angezeigt:
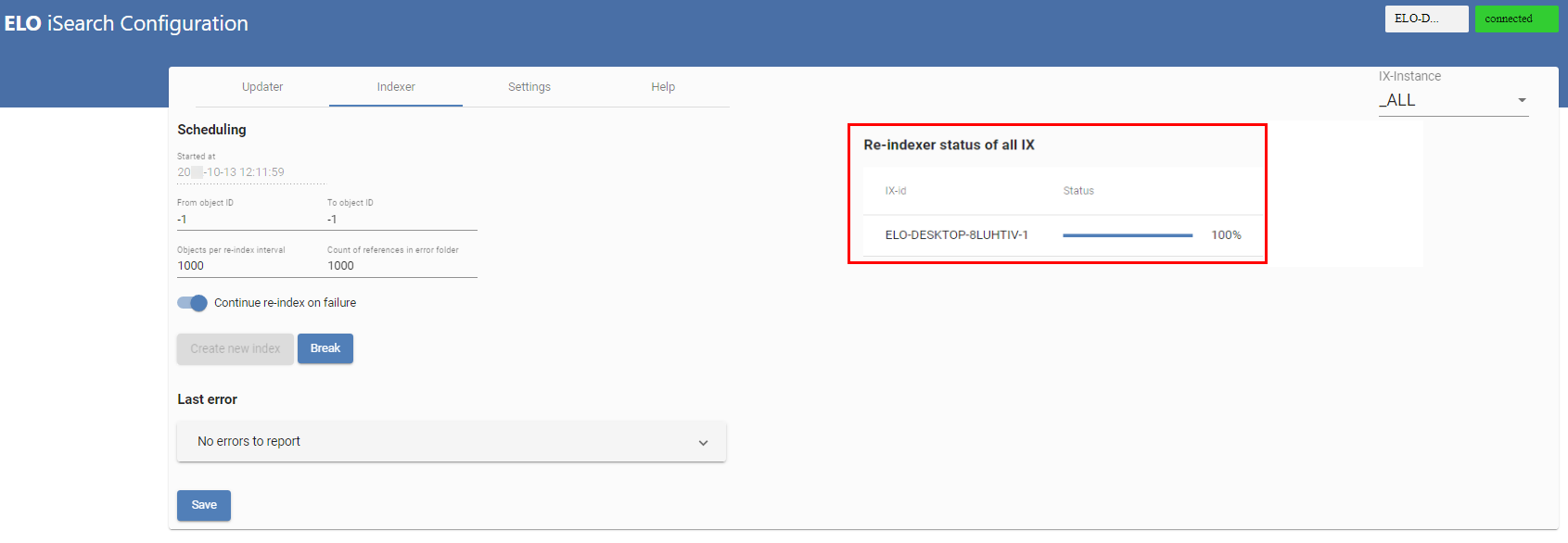
# Indexaufbau im Hintergrund
Bei Upgrades ab der ELO Version 9.3 ist es möglich, über das ELO Server Setup mit der Funktion Upgrade Index einen isolierten ELO Indexserver zu installieren, der den Elasticsearch-Index im Hintergrund aufbaut. Dies ist vor allem bei großen Systemen sinnvoll, bei denen die Re-Indexierung mehrere Tage dauert. Diese Funktion können Sie sowohl bei einem Update zu einer aktuelleren ELO Version verwenden als auch bei Änderungen in den Einstellungen der iSearch.

Diesen Index können Sie dann bei einem ELO Upgrade übernehmen, sodass direkt nach dem Upgrade die volle Suchfunktionalität zur Verfügung steht.
Weitere Details zum Verfahren finden Sie im Abschnitt Indexaufbau im Hintergrund.
# Sizing und Performance
Eine performante Suche stellt die Grundlage zur Akzeptanz des ELO Systems auf Benutzungsebene dar. Daher müssen Sie neben der Optimierung der Datenbank-Performance auch regelmäßig (z. B. halbjährlich, in Abhängigkeit von der hinzukommenden Dokument- und Datenmenge) eine Optimierung der Elasticsearch durchführen. Die Notwendigkeit sollte zum einen auf Benutzungsebene überprüft werden (durch Ausführung komplexerer Suchen), zum anderen aber auch auf Serverebene (durch gelegentliche Log-Datei-Analysen, siehe Abschnitt zu Log-Datei).
# Allgemeine Aussagen zum Sizing
Die Performance der Elasticsearch wird durch folgende Faktoren beeinflusst:
- Arbeitsspeicher, sowohl für die JVM (Java Virtual Machine) der Elasticsearch, weiteren Speicher der Elasticsearch für Caches, der vom Betriebssystem verwaltet wird, als auch für das Betriebssystem allgemein
- Anzahl der Prozessoren/Kerne
- Speichertechnologie bzw. Speicher-Zugriffszeiten
Folgende generelle Aussagen zur Dimensionierung können gemacht werden:
- Arbeitsspeicher (siehe auch den Abschnitt Dimensionierung Arbeitsspeicher):
- Für kleine Umgebungen sind die als Standard definierten 4 GB + 4 GB weiterer freier RAM ausreichend.
- Für mittlere Umgebungen (ca. 10 Mio. Dokumente) sollten ca. 24 GB (12 GB + 12 GB) eingeplant werden.
- Für große Umgebungen gibt es eine Obergrenze von rund 30 GB je JVM, hier ist auf jeden Fall eine Verteilung auf mehrere Server (Cluster) sinnvoll.
- Prozessoren/Kerne:
- Für jede Suche wird ein Thread benötigt, das heißt durch eine höhere Anzahl an Prozessoren/Kernen wird eine bessere Parallelisierung erreicht.
- Festplatten:
- Schnelle Festplatten (SSD) machen sich signifikant bemerkbar. Storage auf SSD-Basis ist für den Betrieb einer Elasticsearch dringend empfohlen.
Auch bereits für mittlere Umgebungen empfehlen wir den Einsatz von ELOenterprise (siehe Lizenzbestimmungen bei der Verteilung von Serverprozessen).
# Dimensionierung Arbeitsspeicher
Bei der Elasticsearch hängt der Speicherverbrauch nicht nur mit der Anzahl und Größe der Dokumente zusammen, sondern zu einem wesentlichen Teil mit der Art der Nutzung durch die Anwender.
Generell muss man beim Speicherverbrauch zwischen dem Java-Heap für den ELO iSearch-Dienst und dem darüber hinaus benötigtem RAM für die Elasticsearch unterscheiden. Hier gibt es die klare Empfehlung, mindestens so viel freien Speicher zusätzlich bereitzuhalten, wie für den Java-Heap konfiguriert ist.
Den Java-Heap konfigurieren Sie fest beim ELO iSearch-Dienst, beispielsweise 10 GB, bei einer neuen ELO Installation initial 4 GB. Dann sollte ebenso viel freier Speicher, der nicht von anderen Applikationen und dem Betriebssystem selbst belegt ist, dem Betriebssystem als Filesystem-Cache für die Elasticsearch zur Verfügung stehen. Die Elasticsearch nutzt diesen Speicher, in dem er vom Betriebssystem als Filesystem-Cache benutzt wird. Inhaltlich sind dort hauptsächlich Indexdaten (fix und temporär) und manche Arten von Caches für Suchanfragen zu finden.
Im Java-Heap befindet sich dagegen die Elastic-Applikation selbst, dazu unter anderem eine Grundmenge Speicher je laufendem Shard (Lucene-Index), sowie der Query-Cache und der Fielddata-Cache.
Für die initiale Größe des Java-Heaps könnte man folgenden Richtwert angeben, der später je nach Nutzungsverhalten angepasst werden muss: 4 GB Grundmenge und dann zusätzlich noch so viel, wie gerade benötigt wird (1 GB für 1 Mio. ELO Dokumente ist ein guter Anfangswert). Alles Weitere ist als Filesystem-Cache viel wertvoller. Als Erfahrungswert wird bei ca. 10 Mio. Dokumenten die richtige Einstellung des Java-Heaps bei 8 bis 16 GB liegen. Der genaue Wert hängt vom Nutzungsverhalten und der Art der Indexfelder ab. Wenn z. B. die Anwender im ELO Client häufig Filter für Indexfelder benutzen, die als tokenized markiert sind und sich sogenannte Kontextterme (d. h. Filter-Werte, die auswählbar sind für dieses Feld) anzeigen lassen und der Index für diese Maske Millionen Dokumente enthält, dann werden alle potenziell vorhandenen Feldwerte in den Java-Heap geladen und landen im Fielddata-Cache. Dies lässt die Größe des Cache und damit des benötigten Java-Heaps stark anwachsen. Dies passiert auch bei einer Sortierung auf solchen Feldern. Wenn dagegen entweder nur auf notTokenized-Feldern aggregiert wird oder keine Filtervorschläge durch Benutzer angefordert werden, beeinflusst dies den Fielddata-Cache nicht, sondern die Feldinhalte landen in temporären virtuellen Files, die dann im oben angesprochenen Filesystem-Cache des Betriebssystems zu finden sein sollten. Dies macht die Vorhersage schwierig, wie viel Java-Heap eingestellt werden sollte.
Beachten Sie
Für jede Maske wird ein separater Elasticsearch-Index aufgebaut. Dieser benötigt (für ein 1-Knoten-System ohne Replica) eine Grundmenge von etwa 50 MB Java-Heap. Eine große Anzahl von Masken erfordert daher einen großen Bedarf an Java-Heap und damit Arbeitsspeicher für die ELO iSearch.
Die Empfehlung ist daher, dass bei der Konfiguration von Masken die Anzahl der Masken möglichst einen zweistelligen Wert nicht überschreiten sollte. Dies gilt sowohl für Masken der ersten als auch für Masken der zweiten Generation.
Für die gesamte Dimensionierung von Java-Heap und restlichem RAM als Filesystem-Cache empfehlen wir, bei einem System zunächst den Speicherverbrauch aller anderen Applikationen zu ermitteln, die noch auf dem gleichen Rechner oder der VM laufen, inklusive dem Betriebssystem selbst. Beispielsweise läuft dort noch ein ELO Indexserver, ein ELO Textreader und ein ELO OCR, deren Verbrauch nicht allein durch den konfigurierten Speicher bestimmt ist, sondern ebenfalls eine große Menge an Filesystem-Cache erfordert. In einer Task-Manager-Applikation Ihres Betriebssystems lässt sich die Gesamtmenge für jede Applikation erkennen. Dann addieren Sie hierzu noch den Verbrauch des Betriebssystems. Der Gesamt-RAM des Systems setzt sich also zusammen aus diesem ermittelten Wert, dem konfigurierten Java-Heap für die Elasticsearch und mindestens gleich vielem freien Speicher für den Elastic Filesystem-Cache.
Beispiel:
ELOix/ELOtr/ELOocr/Betriebssystem benötigen z. B. 12 GB. Die ELO iSearch ist auf 8 GB Java-Heap konfiguriert und benötigt dazu noch 8 GB Filesystem-Cache. Die Gesamtbelegung ist also 12 GB + 8 GB + 8 GB = 28 GB. Damit hätte man dann bei einem 32 GB-System noch Platz für 4 GB. Das ist nicht besonders viel, wenn das Repository wächst.
Bei größeren Systemen empfiehlt es sich, die ELO iSearch auf einer separaten VM oder einem separaten Rechner zu betreiben, damit es nicht zu Konkurrenzsituationen um den Filesystem-Cache mit den anderen Applikationen kommt und das Betriebssystem zu Auslagerungsvorgängen gezwungen ist.
Generell gilt: Nur so viel Java-Heap wie nötig, aber so viel Filesystem-Cache wie möglich.
Information
Wir empfehlen grundsätzlich, den Java-Heap der ELO iSearch im ELO Server Setup einzustellen.
Es gibt zusätzlich die Möglichkeit, den Java-Heap in der Datei <ELO>\config\elastic\ELO-<Instanzname>\jvm.options.d\ELO-<Instanzname>.options im ELO Verzeichnis einzustellen. Nach der Konfigurationsänderung müssen Sie die ELO iSearch neu starten. Die Änderungen gehen allerdings beim nächsten Durchlauf des ELO Server Setups verloren, deswegen ist diese Änderungsmöglichkeit nur für Testzwecke geeignet.
Informationen zum Java-Monitoring der ELO iSearch zu Analyse- und Support-Zwecken finden Sie in der Dokumentation ELO Server > Wartung und Monitoring > Monitoring der Java-Umgebung > Server > ELO iSearch (opens new window).
# Optimierung der Indexierung
Sie können den Bereich der Indexierung nur bedingt optimieren. Die Anzahl der Dokumente zur gleichzeitigen Indexierung wird vom ELO Indexserver (ELOix) bestimmt. Die Erfahrungswerte für den Indexaufbau liegen im Bereich von 2-3 Millionen Dokumenten pro Tag inklusive Volltext-Dokumenten bei einer gut ausgestatteten Umgebung.
Wenn für ein ELO Dokument die Option In Volltext aufnehmen (opens new window) nicht aktiviert ist, wird kein Volltextdokument erzeugt und steht dementsprechend nicht zur Indexierung an. Der Re-Index lässt sich also beschleunigen, wenn weniger Volltextdokumente existieren. Auch die Größe des Volltexts spielt für die Geschwindigkeit eine Rolle. Über die Option maxFulltextContentMB in den Indexserver Configure Options (opens new window) des ELO Indexservers können Sie die maximale Größe des zur Indexierung verwendeten Volltexts eines Dokuments bestimmen. Dokumente mit reinen Metadaten ohne Volltext sind bei der Re-Indexierung um ein Vielfaches schneller.
# Optimierung der Suchgeschwindigkeit
Die Faktoren der Performance wurden schon in Allgemeine Aussagen zum Sizing beschrieben. In großen Umgebungen ergeben sich weitere positive Einflüsse auf die Suchgeschwindigkeit durch eine Erhöhung der Anzahl der Shards je Index, wenn diese auf mehrere Nodes verteilt werden. Sie müssen dabei beachten, dass eine Anpassung der Shard-Anzahl einen Indexaufbau (Re-Index) erfordert. Zur Konfiguration der Anzahl der Shards lesen Sie das Kapitel Festlegung der Shard-Anzahl pro Index.
# Festplattenplatzbedarf für Indexe der Elasticsearch
Der Festplattenplatzbedarf für die Indexe der Elasticsearch hängt von verschiedenen Faktoren ab, die in jedem Kunden-Repository unterschiedlich stark vorhanden sind. Die Hauptfaktoren sind:
- die Anzahl der Dokumente und Ordner
- die Anzahl und Typen der kundenspezifischen und lösungsspezifischen Felder in Masken (Indexfelder)
- für jedes Feld die Menge der Daten, die jeweils enthalten sind. Hier spielt auch die Kardinalität des Felds eine Rolle. Bei Metadaten der Gen. 1 die Mehrwertigkeit über den sogenannten Spaltenindex, bei Metadaten der Gen. 2 die Eigenschaft, ob die jeweilige Aspektzuordnung die Kardinalität MANY hat (d. h. Kardinalität ist gleich MANDATORY_MANY oder OPTIONAL_MANY).
- die Einstellung, ob Volltext erzeugt und indiziert wird, der Anteil von Volltextdokumenten an der Gesamtanzahl der Dokumente und die Einstellung zur Größenbeschränkung des zu indizierenden Volltextes (maxFulltextContentMB)
- ab ELO Version 25.1 die Einstellung, ob AI-Vektoren für den Volltext erzeugt und indiziert werden sowie die Größe des Volltextes
- bei Metadatenfeldern vom Typ Relation werden (konfigurierbar) markierte weitere Felder des referenzierten Dokuments in das referenzierende Dokument mit aufgenommen
- bei Dokumenten, die in einer Region liegen (z. B. bei Dokumenten unterhalb eines Business-Objekts), werden (konfigurierbar) markierte weitere Felder des Regionenobjekts mit in die Dokumente aufgenommen, die in der Region liegen
Da diese Faktoren in jedem Kunden-Repository sehr individuell vorliegen, lässt sich für den zu erwartenden Festplattenplatzbedarf keine hinreichend genaue Abschätzung angeben.
# Platzbedarf für gelöschte Dokumente
In ELO als gelöscht markierte Dokumente sind vollwertige Dokumente in der ELO iSearch. Sie müssen über die API such- und auffindbar sein, wenn im Client mit der Option für inklusive gelöschte Dokumente oder nur gelöschte Dokumente gesucht wird. Deshalb belegen gelöscht markierte Dokumente weiterhin Platz in den Caches der Elasticsearch im Java-Heap und im Filesystem-Cache (RAM). Auch in Bezug auf den belegten Plattenplatz sind es vollwertige Dokumente.
Final gelöschte Dokumente können dagegen nicht gesucht bzw. gefunden werden. Sie belegen keinen Platz mehr im Java-Heap oder Filesystem-Cache (RAM). Sie belegen allerdings weiterhin Festplattenplatz im Index, da sie nach internen Regeln der Elasticsearch bzw. Lucene gelöscht markiert und ggf. später bei Segment-Merge-Vorgängen nach und nach entfernt werden. Wenn dagegen ein Re-Index stattfindet, werden alle Indexe gelöscht und somit auch alle Dokumente in der ELO iSearch.
# Betrieb
Für den Betrieb der Elasticsearch gibt es zwei wichtige Teilbereiche:
- Log-Dateien und deren Inhalt
- Erstellen von Auswertungen
# Log-Datei
Standardmäßig liegen die Elasticsearch-Log-Dateien im ELO Installationsverzeichnis unterhalb des logs-Verzeichnisses.
Relevant ist hier die Log-Datei ELO.log, bzw. ELO-<datum>.log für ältere Log-Dateien.
Im Einzelfall kann auch ein Blick in die Log-Datei des Indexservers (ix-<Repository>.log) sinnvoll sein. Für ELO 11 und ELO 12 können Sie z. B. in der Log-Datei nach dem Begriff queryTerm suchen. Beispielhaft im Folgenden der Output für eine Volltextsuche nach dem Begriff Test:
22:51:34,723 eloix-find-40 eloix-find-40 INFO (ElasticClient.java:183) - find(searchId=[(09A4500F-6BC6-4ECF-EFD6-A9E6B78C5A91)], queryTerm=Test, sort=IDATE\_DESC, highlightedText=false, resultField=true, relevance=true, currentFolderId=0, searchIn=2)
# Auswertungen
Diverse Status der Elasticsearch können Sie per Browser abfragen. Diese können Sie dann gegebenenfalls auch für Monitoring-Lösungen (wie z. B. Nagios) verwenden. Zur Anmeldung ist jeweils ein administratives Tomcat-Konto notwendig. Ausgegeben wird jeweils eine JSON-Datei, die Sie sich wie in dem folgenden Screenshot mit dem Browser Mozilla Firefox auch direkt anzeigen lassen können.
Die URL für Health lautet:
https://<server>:9200/_cluster/health?pretty=true
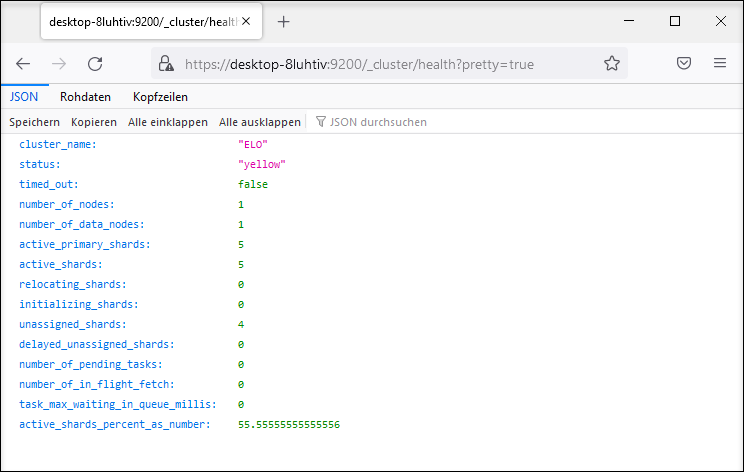
Der Status yellow bedeutet, dass der Index funktionsfähig ist, die Replica-Shards jedoch nicht alle verfügbar sind. In einer Einzelserverumgebung, bei der die Standardeinstellung für Replicas (1) genutzt wird, ist der Status yellow normal.
Die URL für Indexverzeichnis-Namen lautet:
https://<server>:<port>/_cat/indices
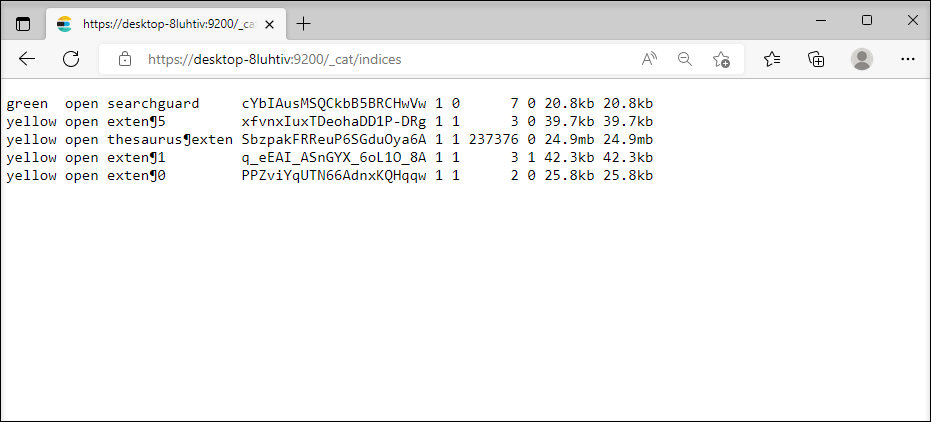
Für jede Maske ist ein Index vorhanden, zu erkennen an der zugehörigen ID.
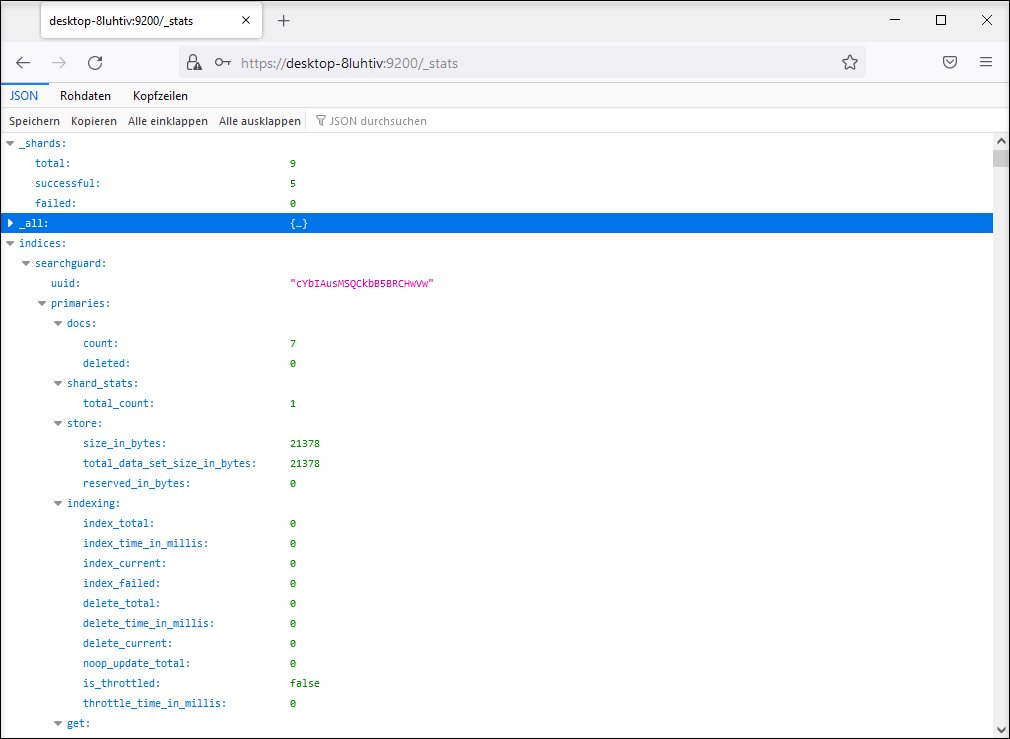
Die URL für Statistikdaten lautet: https://\<server\>:9200/_stats.
Hiermit können Sie prüfen, ob ein neues Dokument in den Index aufgenommen wurde. Nach Neuaufnahme eines Dokuments zeigt die Abfrage in der ersten Zeile nach count einen um 1 erhöhten Wert an.
In derselben Form sind weitere Abfragen möglich. Diese sind in der Online-Dokumentation der Elasticsearch beschrieben.
# Backup-Möglichkeiten und Backup-Strategien
Die Daten der iSearch lassen sich zu 100 % aus der Datenbank über den Indexserver wiederherstellen. Die Entscheidung, ob ein Backup des Elasticsearch-Index angelegt wird, ist demnach von folgenden Faktoren abhängig:
- Welche Downtime der iSearch ist für die Nutzer zumutbar?
Wenn die Downtime möglichst gering sein soll, ist eine Backup-Strategie notwendig, bei der der vorher gesicherte iSearch-Index innerhalb kurzer Zeit in das Produktivsystem gespielt werden kann.
- Wie lange dauert es, den iSearch-Index wiederherzustellen?
Die Dauer der initialen Re-Indexierung kann als Anhaltspunkt für folgende Re-Indexierungen genommen werden. Es muss entschieden werden, ob diese Dauer mit der Downtime für die Nutzer vereinbar ist.
Zum Erstellen eines Backups gibt es zwei Möglichkeiten. Bei beiden Lösungen müssen Sie beachten, dass die Indizes zwischen unterschiedlichen Indexserver-Versionen nicht unbedingt kompatibel sind. Im Anschluss an das Einspielen des Backups ist es notwendig, die Dokumente, die sich seit dem Erstellen des Backups geändert haben, erneut zu indexieren. Dies lässt sich über den Updater-Prozess der iSearch realisieren.
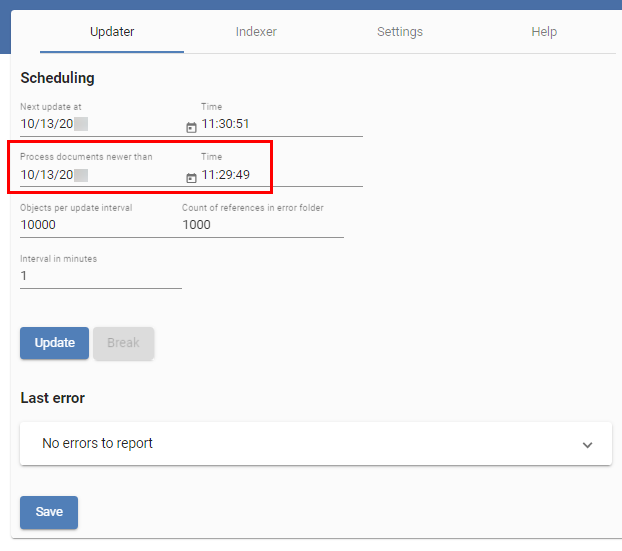
Der Zeitpunkt für Process documents newer than wird auf den Zeitpunkt gesetzt, zu dem das Backup erstellt wurde. Demnach ist es sinnvoll, z. B. täglich oder wöchentlich ein Backup anzulegen, damit die Dauer zum Indexieren der geänderten Dokumente nicht zu lange ist.
Zudem ist zu beachten, dass der Index mit dem Namen searchguard benötigt wird, um die Verschlüsselung mittels SSL über das Search Guard-Plugin zu gewährleisten. Existiert dieser Index nicht, so kann sich auch der Indexserver nicht mit der Elasticsearch verbinden. Haben Sie den searchguard-Index aus Versehen gelöscht, können Sie ihn durch erneutes Durchführen des Server-Setups erzeugen. Außerdem ist der searchguard-Index abhängig vom gewählten administrativen Tomcat-Konto, sodass der Index bei unterschiedlichen Konten oder Passwörtern nicht einfach kopiert werden kann, sondern durch das Server-Setup erzeugt werden muss.
# Bestehenden Index kopieren
Den bestehenden Index können Sie aus dem Dateisystem kopieren und zu einem späteren Zeitpunkt wieder einspielen. Dazu kopieren Sie den kompletten Ordner unter <Installationsverzeichnis>/data/<…><Servername>/index als Backup. Sollte das Backup benötigt werden, ersetzen Sie den Inhalt des oben genannten Ordners mit dem Backup.
Den iSearch-Dienst sollten Sie vor dem Kopieren stoppen, um Zugriffsfehler zu vermeiden.
# Snapshot mittels Elasticsearch erstellen
Elasticsearch selbst bietet die Möglichkeit, sogenannte Snapshots der bestehenden Indizes anzulegen. Werden regelmäßig Snapshots erzeugt, wird nicht jedes Mal eine komplette Kopie erzeugt, sondern nur die geänderten Dateien gespeichert und so der benötigte Speicherplatz reduziert.
Die Anleitung dazu finden Sie hier:
Beachten Sie
Um einen Snapshot wiederherstellen zu können, müssen Sie der Konfigurationsdatei der Elasticsearch (<Installationsverzeichnis>/config/elastic/<Servername>/elasticsearch.yml) folgende Zeile hinzufügen: searchguard.enable_snapshot_restore_privilege: true
# Tipps und Tricks
# ELO iSearch-Konfiguration
Über die Konfigurationsseite des Indexservers können Sie die ELO iSearch Configuration aufrufen, die ab ELO 11 zur Verfügung steht:
https://<server>:<Port>:/ix-<Repository>/manager/esconfig/#/isearchConfig
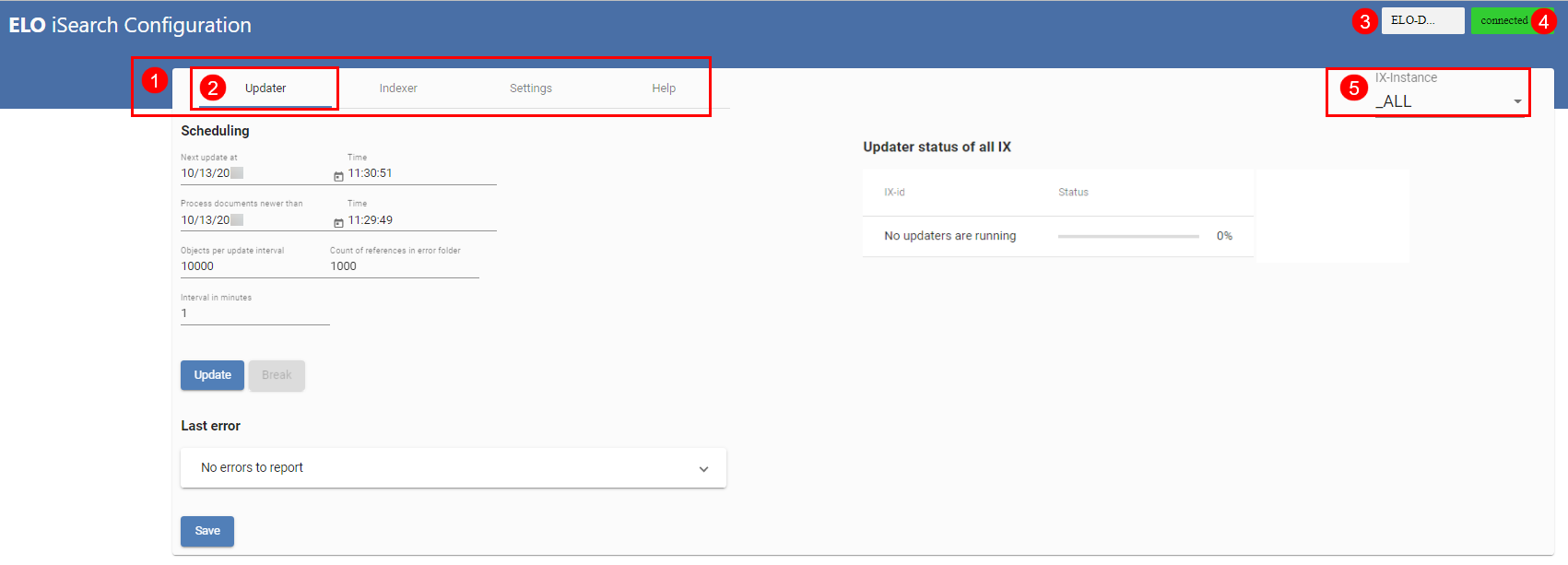
In der obigen Abbildung sehen Sie die Konfiguration der ELO iSearch. Sie können über die ELO iSearch Configuration die verschiedenen Funktionalitäten der iSearch aufrufen (1), der aktive Tab ist mit einem blauen Unterstrich markiert (2). Oben rechts (3) sehen Sie den Namen der ELOix-Instanz, über die die ELO iSearch Configuration aufgerufen wurde, deren Verbindungsstatus zur iSearch (4) ist connected bzw. disconnected.
Ab ELO 11 werden die Einstellungen für die iSearch in der Tabelle eloixopt gespeichert und sind demnach, wie auch die Indexserveroptionen, instanzspezifisch, bzw. für alle Instanzen gespeichert (_ALL). In der Tabelle haben alle iSearch-Einstellungen das Präfix esearch. Über die ELO iSearch Configuration können Sie die Einstellungen ebenso für alle Instanzen (_ALL) oder instanzspezifisch anzeigen lassen und bearbeiten (5).
# Updater
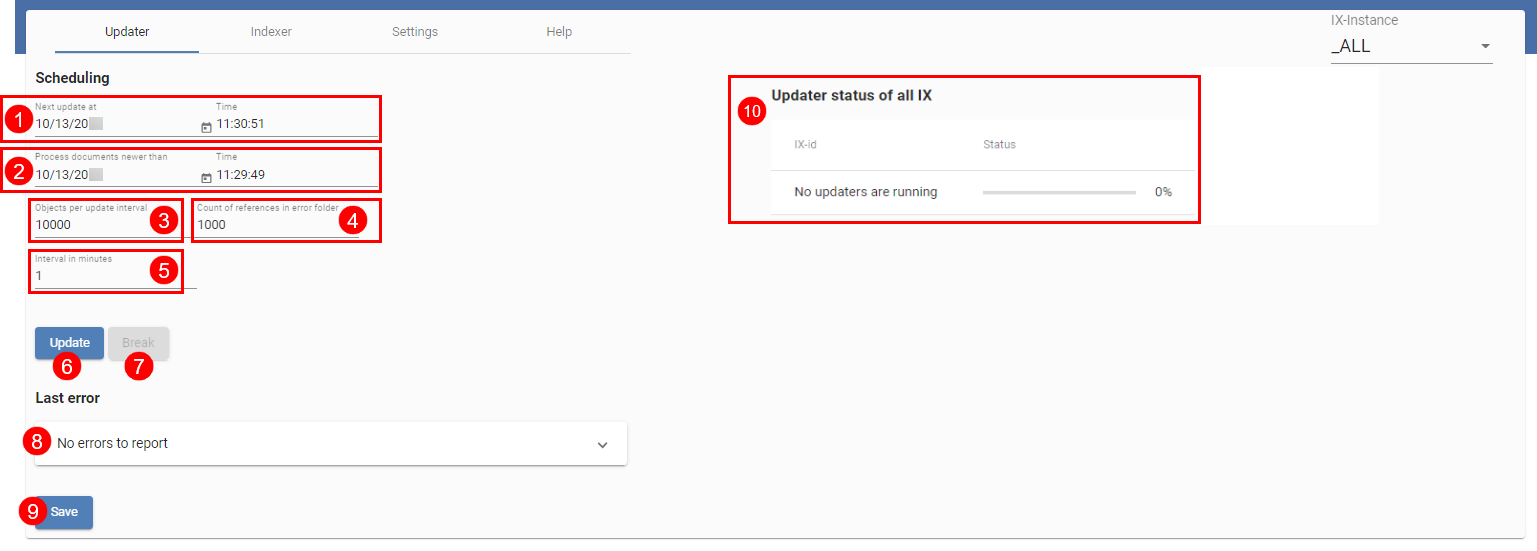
In der obigen Abbildung sehen Sie die Übersicht über den Updater. Diesen benötigen Sie für die regelmäßige Aktualisierung der iSearch. Er sorgt zudem dafür, dass neue und geänderte Objekte an die iSearch gesendet werden. In der obersten Zeile (1) sehen Sie, wann der Updater das nächste Mal startet und in der nächsten Zeile (2), ab welchem Zeitpunkt Dokumente verarbeitet werden. Beide Werte können Sie einstellen. In der Standardkonfiguration läuft der Updater jede Minute (5) und verarbeitet maximal 1000 Objekte (3) in der kleinsten Zeiteinheit (1 Minute). Beachten Sie, dass die Anzahl der ausgewählten Objekte zeitgleich im Speicher des ELOix gehalten wird, den Wert sollten Sie daher nur mit Bedacht anpassen.
Kommt es zu Problemen beim Indexieren eines Dokumentes, wird eine Referenz auf das Dokument in ELO unter folgendem Pfad angelegt:
Administration // Fulltext Configuration // Update Errors
Dadurch können Sie leicht kontrollieren, ob es zu Fehlern kam und dafür sorgen, dass die Dokumente erneut an die iSearch gesendet werden, indem z. B. der Dialog Metadaten geöffnet wird. Die maximale Anzahl an Dokumenten in diesem Ordner stellen Sie in (4) ein. Stellen Sie 0 ein, werden keine Referenzen angelegt.
Nehmen Sie Änderungen vor, müssen Sie diese mit Save speichern (9).
Eine Übersicht über die laufenden Updater-Prozesse ist im Bereich Updater status of all IX (10) dargestellt. Einen Update-Prozess können Sie auch manuell über den Button Update (6) starten sowie über den Button Break (7) unterbrechen. Beachten Sie hierbei, dass sich das Starten und Unterbrechen immer auf die aktuelle ELOix-Instanz bezieht.
Der letzte Fehler des Updater-Prozesses wird in Last Error (8) angezeigt.
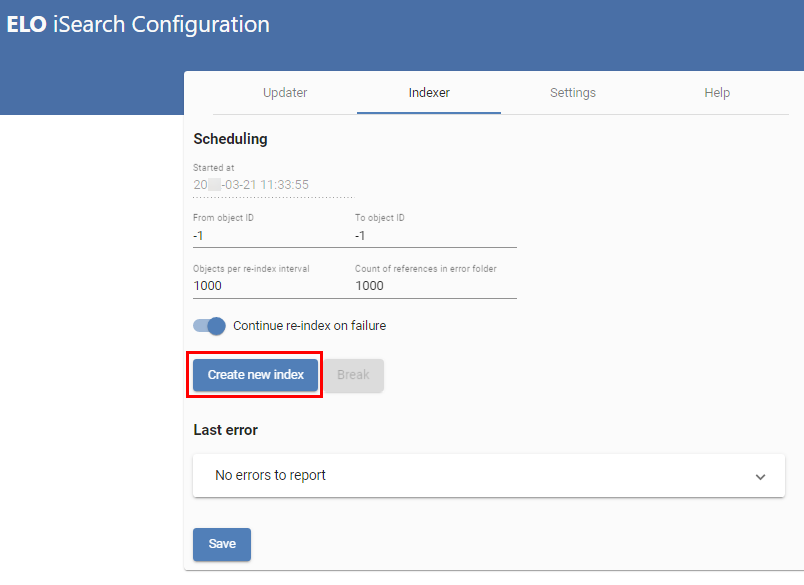
# Indexer
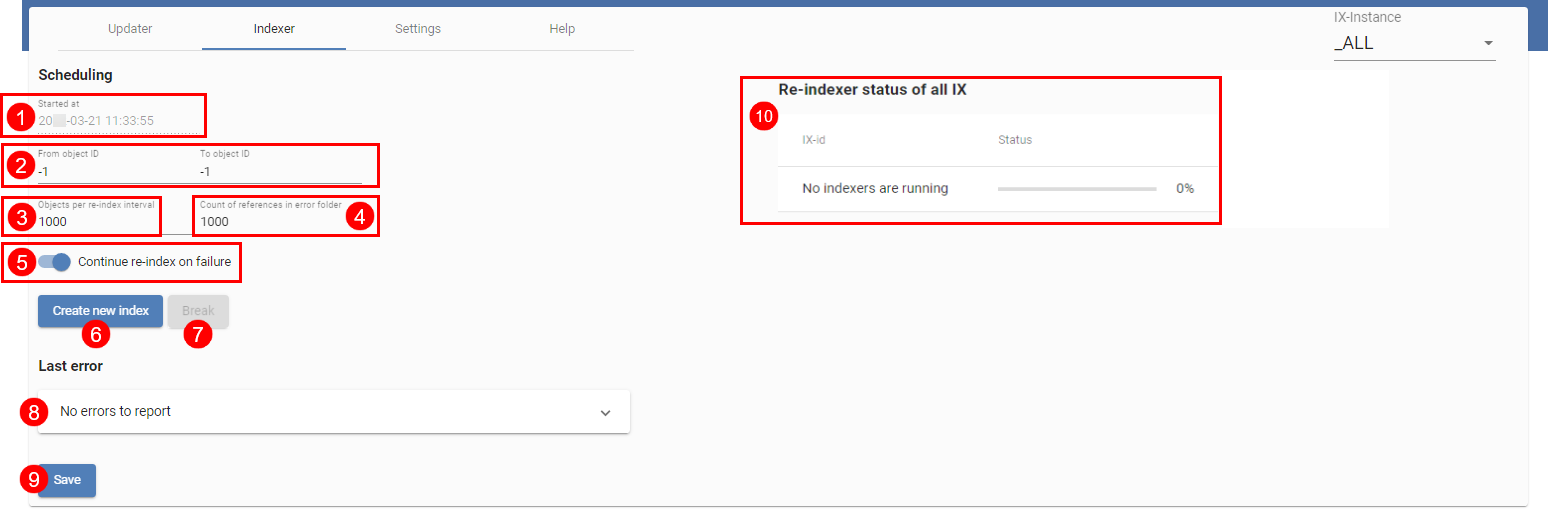
Über den Indexer (obige Abbildung) nehmen Sie die initiale Befüllung der iSearch mit den Objekten aus ELO. Dazu werden alle vorhandenen Objekte an die iSearch gesendet. Gestartet wird mit den Objekten mit der höchsten ID, indexiert wird absteigend. Dadurch sind neue Objekte früher auffindbar, sofern der Index sofort produktiv verwendet wird.
In der obersten Zeile (1) ist der Startzeitpunkt des letzten Re-Index-Prozesses zu sehen. Über (2) und (3) wählen Sie die Objekt-IDs aus, die indexiert werden. Möchten Sie einen kompletten Re-Index durchführen, müssen Sie beide Werte auf -1 setzen. Dies führt auch dazu, dass der bestehende Index gelöscht wird. Möchten Sie jedoch nur bestimmte Objekte erneut einem bestehenden Index hinzufügen, können Sie dies auch über die IDs steuern.
Die Einstellungen für die Objekte pro Indexierungsintervall (3) und Referenzen in ELO (4) entsprechen denen des Updaters. Die Referenzen werden im Ordner unter folgendem Pfad abgelegt:
Administration // Fulltext Configuration // Re-Index Errors
Dieser Wert ist der Gleiche, sowohl für den Updater als auch für den Indexer.
Die Einstellung Continue Reindex on Failure (5) gibt an, ob im Falle eines Fehlers der Re-Index-Prozess unterbrochen oder fortgesetzt werden soll. Möchten Sie ihn fortsetzen, ist ein regelmäßiges Kontrollieren der Log-Ausgaben unablässig.
Der letzte Fehler des Re-Index-Prozesses wird in Last Error (8) angezeigt.
Die Einstellungen müssen Sie über den Button Save (9) speichern.
Ein Re-Index kann gestartet (wenn beide Objekt-IDs auf -1 gesetzt sind) bzw. fortgesetzt (6) sowie unterbrochen (7) werden. Wie auch beim Updater müssen Sie beachten, dass dies sich immer auf die ELOix-Instanz bezieht, mit der die Config-Seite aufgerufen wurde.
Eine Übersicht über aktive Re-Index-Prozesse ist in (10) dargestellt.
# Settings
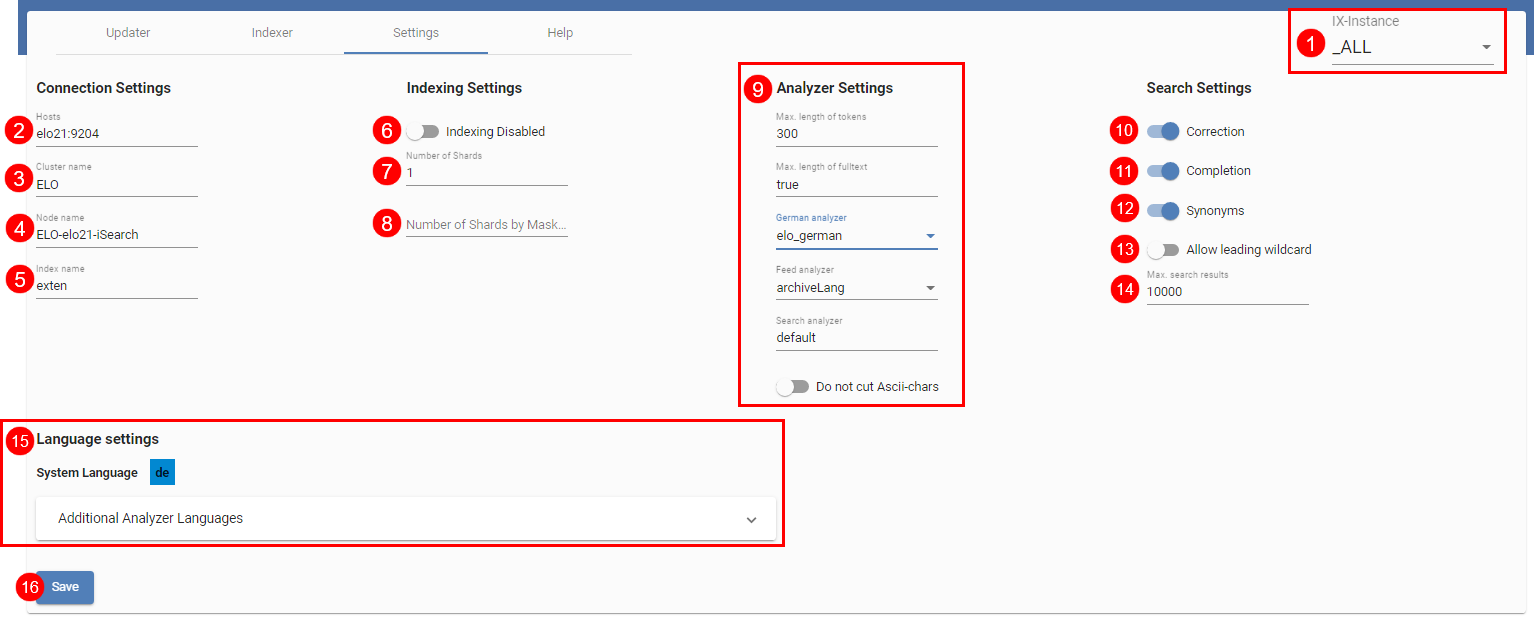
Eine Übersicht über die weiteren Einstellungsmöglichkeiten der iSearch ist in der oberen Abbildung dargestellt. In IX-Instance (1) wählen Sie aus, ob die Einstellungen für alle Instanzen oder instanzspezifisch vorgenommen werden sollen (siehe auch die nächste Abbildung ELO iSearch Configuration, Tab 'Setting', Einstellungen instanzspezifisch vornehmen).
Die Details zum Verbindungsaufbau zwischen ELOix und Elasticsearch werden in (2), (3) und (4) angegeben. Der Name des Elasticsearch-Index (5) entspricht im Standard dem Namen des Repositorys in Kleinbuchstaben.
Des Weiteren können Sie angeben, ob ein ELOix überhaupt zum Senden von Objekten an die iSearch verwendet werden soll (6). Ist diese Einstellung aktiv, ist die Volltextsuche über die iSearch trotzdem noch aktiv.
Die Anzahl der Shards bzw. Shards pro Maske wird mit (7) und (8) eingestellt. In Kapitel Festlegung der Shard-Anzahl pro Index wird näher auf diese Einstellungen eingegangen.
Die Analyzer-Einstellungen (9) beziehen sich darauf, wie Text verarbeitet wird, der an die Elasticsearch gesendet wird. Im Normalfall verwenden Sie die vorhandenen Voreinstellungen.
Die Einstellungen (10) bis (14) beziehen sich auf die Suche. Es ist einstellbar, ob Korrekturvorschläge (10) oder Synonyme (12) zur Suchanfrage zurückgegeben werden und ob die Autovervollständigung (11) bei der Sucheingabe aktiv ist. Des Weiteren können Sie die Suche mit einem Wildcard-Zeichen am Anfang des Suchwortes aktivieren (13). Dies ist standardmäßig deaktiviert, da eine Suche mit führendem Wildcard-Zeichen die Elasticsearch stark auslasten kann. Außerdem können Sie die maximalen Suchergebnisse einstellen (14), die über die ELOix-API-Aufrufe findFirstSords() und findNextSords() zurückgegeben werden.
Die Spracheinstellungen der iSearch können Sie mittels Language Settings (15) bearbeiten. Die System- bzw. Repository-Sprache wird über das ELO Server Setup eingestellt und kann nicht bearbeitet werden. Je nach verfügbaren Lizenzen können Sie weitere Sprachen auswählen. Die eingestellten Sprachen bestimmen bei der Indizierung, ob für ein Dokument mit einer erkannten Sprache spezielle sprachspezifische Analyzer-Schritte bei der Erzeugung der Tokens verwendet werden oder nicht. Beispielsweise kann für die Sprache deutsch ein Decompounder-Filter benutzt werden, um zusammengesetzte Wörter zu zerlegen. Das führt dazu, dass auch nicht zusammengesetzte Teilwörter gefunden werden können. Für die Sprache englisch können z. B. typische Stoppwörter entfernt werden. Wenn während der Indizierung für ein Dokument eine Sprache erkannt wird, die nicht in den eingestellten Sprachen enthalten ist, wird das Dokument trotzdem indiziert, allerdings nur mit den Analyzer-Schritten, die nicht sprachspezifisch sind (Fallback-Analyzer).
Alle Einstellungen müssen Sie über den Button Save speichern (16). Beachten Sie, dass die Einstellungen (5), (7), (8), (9) und (15) einen Re-Index benötigen, damit sie für alle Daten gelten und dies nicht zu unterschiedlichen Daten in der iSearch führt.
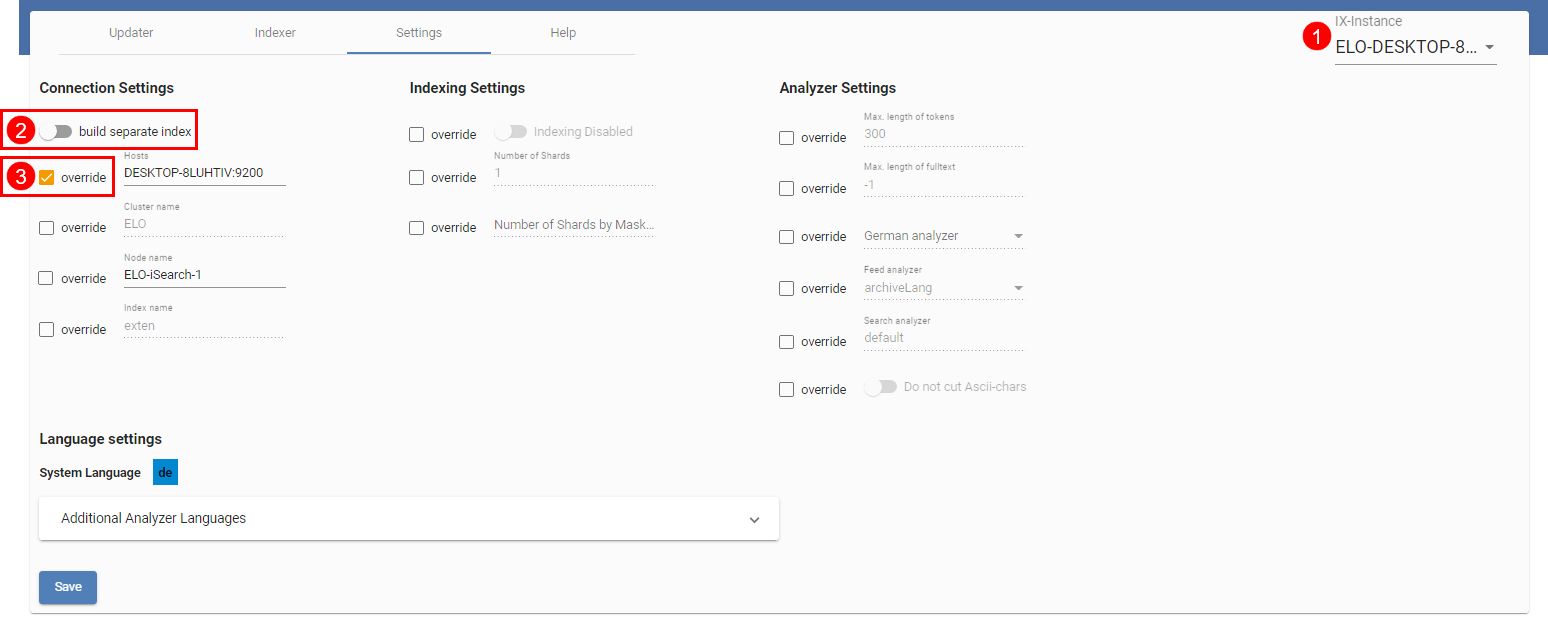
Die Abbildung zeigt beispielhaft die Einstellungsseite für die Instanz ELO-DESKTOP-8LUHTIV (1). Alle Einstellungen, bei denen die Override-Checkbox aktiv ist (3), überschreiben die Einstellung, die für alle Instanzen vorgenommen wird.
Die Einstellung build separate index (2) können Sie nur instanzspezifisch vornehmen. Ist diese Einstellung aktiv, wird mit diesem Indexserver ein separater Index aufgebaut – allerdings nur dann, wenn sich entweder die Verbindungseinstellungen, von denen für die anderen Instanzen unterscheiden oder der Indexname unterschiedlich ist. Im Kapitel Indexaufbau im Hintergrund wird dies näher erläutert.
# Dienstekonfiguration der Elasticsearch
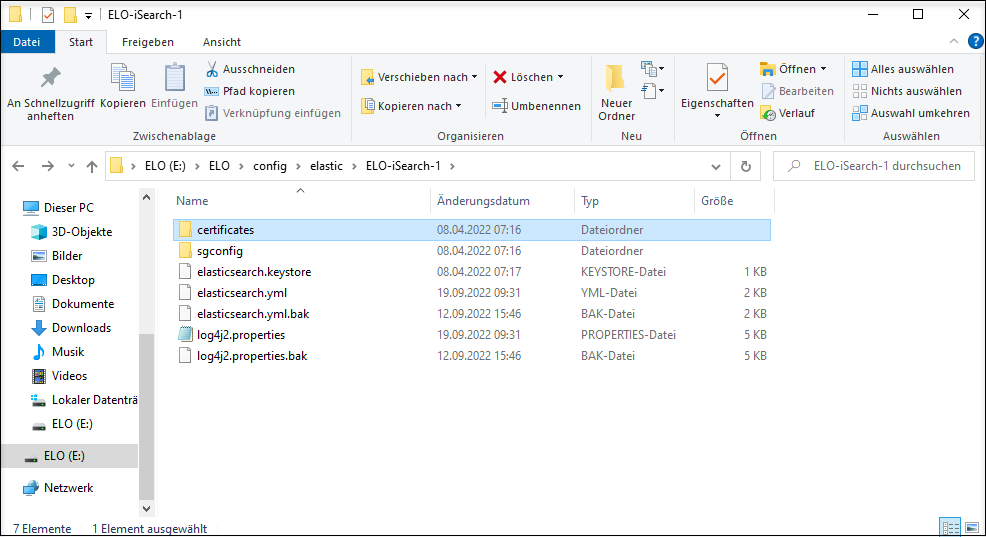
Die Konfiguration des Elasticsearch-Dienstes erfolgt über mehrere Dateien und Verzeichnisse.
Im Einzelnen haben die Dateien und Verzeichnisse folgende Inhalte:
elasticsearch.yml: Zentrale Konfigurationsdatei der Elasticsearch. Detaillierte Informationen lesen Sie unter folgendem Link: https://www.elastic.co/guide/en/elasticsearch/reference/current/important-settings.html (opens new window)
Beachten Sie
Fügen Sie in der Konfigurationsdatei elasticsearch.yml außer auf Anweisung des ELO Supports keine Optionen hinzu.
log4j.properties: Logging-Einstellungen
sgconfig: Verzeichnis mit Konfigurationen des Search Guard Plugins
certificates: Key- und Truststore für die SSL-Kommunikation mit dem ELO Indexserver
# SSL-Kommunikation
Ab der ELO ECM Suite 10.2 kommunizieren die ELO Indexserver verschlüsselt mit der Elasticsearch. Dazu werden vom ELO Server Setup bei der Installation selfsigned Zertifikate und entsprechende Key- und Truststores angelegt. Die Key- und Truststores werden unterhalb der jeweiligen config-Verzeichnisse (Indexserver und Elasticsearch) angelegt und können mit Java-Standardmitteln (z. B. keytool.exe) für die Prüfung der Zertifikate geöffnet werden. Verwenden Sie das Passwort des administrativen Tomcat-Kontos.
# Indexserver-Plugins
Ab ELO 11 ist es möglich, den Indexserver durch sogenannte OSGi-Plugins zu erweitern. Beispielsweise befindet sich die Elasticsearch-Anbindung selbst in einem solchen Plugin. Mit dieser Aufteilung ist es zukünftig möglich, mit einer älteren Indexserver-Version auf einen neueren Elasticsearch-Index zuzugreifen. Für jeden Indexserver wird ein Plugin-Verzeichnis konfiguriert.
# Festlegung der Shard-Anzahl pro Index
Ab ELO 11 wird pro Maske ein Index angelegt. In der Standardeinstellung besteht jeder Index aus einem Shard. Durch die Aufteilung in einen Index pro Maske wird auch im Cluster schon ein Performance-Gewinn erreicht, da die Indizes auf mehrere Nodes aufgeteilt werden.
Zusätzlich ist es sinnvoll, besonders große Indizes in mehrere Shards aufzuteilen. Der Vorteil liegt darin, dass Suchanfragen dann parallel auf allen Shards ausgeführt werden. Allerdings werden maximal so viele Suchanfragen innerhalb eines Nodes parallel ausgeführt wie Prozessoren vorhanden sind.
Die Anzahl an Shards richtet sich demnach nach den enthaltenen Daten. Elasticsearch empfiehlt eine Shard-Größe von 20 bis 40 GB. Zu kleine Shards führen zu einer Überlastung in der Kommunikation zwischen den Shards, da die Daten zwischen den Shards synchronisiert werden müssen. Masken, die sehr viele Sords mit Volltext enthalten, sollten demnach möglichst in mehrere Shards aufgeteilt werden.
Die Anzahl an Shards pro Maske kann über die ELO iSearch Configuration vorgenommen werden, erfordert allerdings einen Indexaufbau (Re-Index) aller Daten.
# Festlegung der Replica-Anzahl pro Index
Replicas sind gewissermaßen Kopien eines Index. Es kann jeder beliebige Wert gewählt werden, auch 0. Für jeden Shard wird ein Primary-Shard erzeugt, sowie im Cluster die angegebene Anzahl an Replica-Shards. Primary-Shards und Replica-Shards werden immer auf unterschiedlichen Nodes angelegt, um im Falle eines Ausfalls auch weiterhin die Daten bereitstellen zu können. Fällt ein Node aus, werden die Primary-Shards, die bisher auf diesem Node allokiert waren, auf einem anderen Node allokiert. Die Replica-Shards werden auf andere Nodes verteilt, um weiterhin die bestmögliche Ausfallsicherheit und Performance zu gewährleisten.
Der weitere Vorteil von Replica-Shards ist die Parallelisierung von Suchanfragen: Die Elasticsearch verteilt Suchanfragen auf unterschiedliche Primary-Shards und Replica-Shards, um die Last der Suchanfragen zu verteilen.
Der Health-Zustand eines Indizes ist abhängig davon, welche Shards verfügbar sind: Ist der Primary-Shard vorhanden, ist der Zustand gelb, sind zusätzlich alle Replica-Shards verfügbar, ist der Zustand grün.
Die Menge der Replica-Shards sollten Sie an die Anzahl der Nodes im Cluster anpassen, sodass sich die Shards sinnvoll auf mehrere Nodes verteilen können, um Ausfallsicherheit zu gewährleisten. Andererseits benötigt jede Replica genauso viel Speicherplatz wie die Primary-Shard.
Die Standardeinstellung für die Anzahl an Replicas ist 1. So wird in einem Cluster von mehr als einer Instanz jeder Shard einmal repliziert, ist also insgesamt zweimal vorhanden. Eine Änderung an der Anzahl der Replicas erfordert keine Re-Indexierung.
Um eine Re-Indexierung in einem Cluster zu beschleunigen, können Sie für die Dauer der Re-Indexierung die Anzahl an Replicas auf 0 setzen und nach dem Beenden erhöhen. Ist die Anzahl an Replicas > 0, werden die Daten sowohl im Primary-Shard als auch in jedem Replica-Shard zeitgleich indexiert. Das bedeutet, dass die Analyse und Umwandlung in Elasticsearch-Daten mehrmals parallel stattfinden. Wird die Anzahl an Replicas auf 0 gesetzt, werden die Daten während der Re-Indexierung nur in einem Node verarbeitet. Sobald die Anzahl an Replicas erhöht wird, werden die bereits indexierten Primary-Shards auf die anderen Nodes kopiert, was in der Regel deutlich schneller geht. Natürlich ist dadurch während der Re-Indexierung keine Ausfallsicherheit gewährleistet.
Die Einstellung ist bezogen auf einen Index und kann z. B. mit dem curl-Tool (https://curl.haxx.se/ (opens new window)) exemplarisch folgendermaßen für die Maske mit der ID 42 des Repositorys repository auf 2 geändert werden:
curl -X PUT "localhost:9200/repository¶42/_settings" -H 'Content-Type: application/json' -d'
{
"index" : {
"number_of_replicas" : 2
}
}
'
Möchten Sie die Einstellung für alle Indizes ändern, können Sie die Angabe des Index weglassen und die URL localhost:9200/_settings verwenden.
# Tokenisierung
Die Option Tokenisierung deaktivieren einer Feldvorlage schaltet die Suchregeln und -muster für dieses Feld aus. Es erscheinen dann in der Liste des Filters die exakten Werte der Metadaten. Die Suche arbeitet für dieses Feld dann ebenfalls in einem exakten Modus. Teilbegriffe werden in diesem Fall nicht berücksichtigt.

Bei aktiven Suchregeln und -mustern erscheinen in der Liste des Filters nur einzelne Wörter, sowohl die Originale als auch die erzeugten Stammformen. Die Suchmöglichkeiten in diesem Filter entsprechen dann denen des Eingabefeldes der Suche.
# Einbinden eigener Thesauri
Die Wörterbücher für den Thesaurus der ELO iSearch können Sie für ein Repository individuell anpassen. Die benötigten Dateien liegen in ELO unter folgendem Pfad:
Administration // Fulltext Configuration // Thesaurus
In diesem Pfad befindet sich für jede Sprache ein Unterverzeichnis mit dem Länderkürzel, in dem sich jeweils drei Dokumente befinden.

<Sprache>_thesaurus: Der von ELO ausgelieferte Thesaurus für diese Sprache. Diese Datei sollten Sie nicht ändern, damit sie bei einem Update gegen eine neuere Version ausgetauscht werden kann.
<Sprache>_add: In diesem Dokument können Sie zusätzliche Begriffe eintragen, welche als Synonyme in den Thesaurus aufgenommen werden sollen.
<Sprache>_stop: Über dieses Dokument können Sie einzelne Begriffe aus dem Thesaurus ausschließen, wenn diese Ihnen für Ihren Einsatz unpassend erscheinen.
Beachten Sie
Nach einer Änderung der Dokumente muss der ELO Indexserver neu gestartet werden, damit der Thesaurus anhand der geänderten Dateien neu aufgebaut werden kann.
# Cluster-Betrieb
Wie Sie ELO in einem Cluster betreiben, lesen Sie in der Dokumentation zur ELO iSearch in ELO Server - Installation und Betrieb (opens new window).
# Empfehlungen bei Fehlermeldungen
# Fehlermeldung enthält Text 'pending translog recovery'
Nach einem ungeplanten Neustart des ELO iSearch-Dienstes kann es im iSearch-Log zu Fehlermeldungen kommen, die den Text pending translog recovery enthalten.
Beispiel:
[2023-06-29T13:22:51,662][WARN ][o.e.i.f.SyncedFlushService] [ELO-iSearch] failed to flush shard [contelo¶2][0], node[8NAibzRYQtqFpTY_Fl7mug], [P], recovery_source[existing store recovery; bootstrap_history_uuid=false], s[INITIALIZING], a[id=o1RcLpTjTdWLSNrMOnzlGA], unassigned_info[[reason=CLUSTER_RECOVERED], at[2023-06-29T11:05:49.208Z], delayed=false, allocation_status[deciders_throttled]] on inactive
java.lang.IllegalStateException: [contelo¶2][0] flushes are disabled - pending translog recovery
at org.elasticsearch.index.engine.InternalEngine.ensureCanFlush(InternalEngine.java:2572) ~[elasticsearch-7.15.2.jar:7.15.2]
Diese Meldungen können sehr zahlreich sein und erscheinen dann, wenn die ELO iSearch beendet wurde und vor dem Herunterfahren nicht mehr dazu kam, alle Transaktionen in den Index zu überführen (z. B. bei Hauptspeichermangel oder wenn die Speicherplatte voll ist). Beim Hochfahren versucht die Elasticsearch dann das Translog-File in den Index zu überführen. Das kann bei vielen Daten eine Stunde oder sogar mehrere Stunden dauern. Während dieser Zeit sind die Indexe nicht verfügbar.
Empfehlung:
Hier müssen Sie zunächst abwarten, bis das gesamte Translog in den Index überführt ist und diese Meldungen nicht mehr erscheinen. Danach sollten Sie untersuchen, welches ursprüngliche Problem zum Herunterfahren des ELO iSearch-Dienstes geführt hatte.
Vermeiden Sie es, eine Re-Indexierung über die Konfigurationsseite der ELO iSearch zu starten, während diese Meldungen erscheinen. In der Regel ist der Index nach Abschluss des Translog-Recovery wieder konsistent und erfordert keine Re-Indexierung.
Wenn während des Translog-Recovery das System hart heruntergefahren wird, kann es zu endgültig korrupten Indexdaten kommen, die durch das Translog-Recovery nicht mehr behebbar sind. Die Folge ist die Notwendigkeit einer Re-Indexierung oder sogar einer Neuinstallation des ELO iSearch-Dienstes.
# Abbruch der Re-Indexierung wegen zu vieler Feed-Beiträge
Wenn es bei einem Re-Indexierungsvorgang der iSearch zu einem Abbruch kommt, kann in seltenen Fällen als Ursache eine extrem große Menge an Feed-Beiträgen infrage kommen. Dies kann hervorgerufen werden durch fehlerhafte Automatismen wie z. B. Importprozesse oder Scripte, die Dokumente ablegen und dabei ungewollt eine enorme Anzahl an Feed-Beiträgen ggf. mit Fehlermeldungen als Inhalt erzeugen.
Das lässt sich an zwei Stellen erkennen:
Der ELO Indexserver bricht ab mit der Fehlermeldung:
java.lang.OutOfMemoryError: Java heap space.Im Log des ELO Indexservers sind in Bezug auf die feedaction-Tabelle SQL-Exceptions mit
read timed outzu sehen. Dabei sind zusätzlich zuvor Einträge mit einer hohen Anzahl an Feed-Beiträgen pro einzelnem Dokument zu sehen.Beispiel:
19:20:58.529 INFO esin-8 esin-8 (FeedIndexer.java:108) - [821022] indexFeed=true: posts=#145239
Um festzustellen, ob zu viele Feed-Beiträge die Ursache für den Abbruch sind, können Sie mit einer Abfrage in der Datenbank ermitteln, zu welchen SORDs (d. h. ELO Dokumenten) eine sehr hohe Anzahl an Feed-Beiträgen existiert.
Beispiel einer SQL-Abfrage:
select count(*), objid
from documentfeed d
inner join feedaction f on d.feedguid=f.feedguid
inner join objekte o on d.objguid = o.objguid
group by objid
having count(f.feedguid) > 1000
order by 1 desc
Die Anzahl 1000 dient beispielhaft als eine Schwelle für viele Feed-Beiträge pro ELO Dokument. Wenn hier sehr hohe Werte (Zehntausende oder Millionen) in der ersten Ergebnisspalte zu sehen sind, müssen Sie die Ursache für diese Feed-Einträge finden und fehlerhafte Automatismen korrigieren.
Information
Bei kleinen ELO Systemen kann auch eine Gesamtmenge von vielen Millionen Feed-Beiträgen eine erhöhte Last oder einen erhöhten Speicherverbrauch des ELO Indexservers verursachen. Hier ist die Gesamtanzahl an Einträgen in der Tabelle feedaction relevant.
Bringen Sie das System nach der Korrektur von fehlerhaften Automatismen folgendermaßen wieder in einen arbeitsfähigen Zustand.
Vorgehen
- Sichern Sie vorab die Datenbank über ein Backup.
- Stoppen Sie alle ELOix-Instanzen für die Dauer der Korrektur.
- Identifizieren Sie die feedguid zur betreffenden objguid in der Tabelle documentfeed.
- Löschen Sie in der Tabelle feedaction die Zeilen mit der feedguid, die nicht mehr benötigt werden oder fehlerhaft sind.
- Optional: Identifizieren Sie in der Tabelle feedactionhist (Änderungshistorie) die entsprechenden actionguids zur ermittelten feedguid und löschen Sie dann in der Tabelle feedactionhist die zu diesen actionguids passenden Zeilen. Diese wirken sich nicht direkt auf den Re-Index aus, sind allerdings überflüssig, wenn die Haupt-Einträge gelöscht sind.
- Falls alle zugehörigen Zeilen in der Tabelle feedaction gelöscht wurden (d. h. falls alle diese Feed-Posts fehlerhaft oder ungewollt sind), löschen Sie in der Tabelle documentfeed die Zeile mit dieser feedguid (feedaction.feedguid = documentfeed.feedguid).
Alternativ:
Falls nur alte oder nicht mehr benötigte Feed-Beiträge bereinigt werden sollen, reicht es, wenn Sie die Schritte 1 bis 6 außer Schritt 3 durchführen. Dabei können z. B. alle noch benötigten Einträge in eine zusätzliche Tabelle kopiert werden und danach diese in feedaction umbenannt werden.
# Powersuche
Die Powersuche der ELO iSearch bietet die Möglichkeit, komplexe Anfragen an die iSearch zu stellen und direkt auf deren Syntax zuzugreifen.
Die Powersuche der ELO iSearch erlaubt es Ihnen, direkt auf die zugrundeliegende Elasticsearch zuzugreifen. Dadurch bieten sich zwei neue Möglichkeiten: Zum einen kann auf Felder, die nicht über einen Filter auswählbar sind, direkt zugegriffen werden. Zum anderen können über die von Elasticsearch angebotene Syntax sehr komplexe Anfragen gestellt werden.
Der direkte Zugriff auf die internen Strukturen ist gleichzeitig auch der Nachteil der Powersuche, denn die Schreibweise ist sehr technisch und erfordert Wissen über die verwendeten internen Datenstrukturen. Dieser interne Aufbau kann sich zudem in kommenden ELO Versionen ändern, sodass vorhandene Suchabfragen nicht mehr richtig oder gar nicht mehr funktionieren.
Achtung
Die Powersuche sollte nur in besonderen, einzelnen Fällen benutzt werden, wenn die normalen Suchmöglichkeiten nicht ausreichen (z. B. bei administrativen Spezialanfragen).
# Anwendung der Powersuche
Die Powersuche kann sowohl über den ELO Java Client als auch den ELO Web Client verwendet werden. Die Suchanfrage wird über die Suchzeile eingegeben und mit einem = ausgelöst, wie im folgenden Beispiel zu sehen ist.

Mit der Powersuche werden Anfragen über den ELO Indexserver direkt an die Elasticsearch geschickt. Der ELO Indexserver fügt eine Berechtigungsüberprüfung hinzu, sodass Sie trotz Powersuche immer nur Dokumente angezeigt bekommen, für die Sie eine Berechtigung haben.
Die Syntax der Powersuche entspricht der Syntax der QueryStringQuery, wie sie von Elasticsearch unter diesem Link dokumentiert wird:
Für die Benutzung ist wichtig, dass Sie Sonderzeichen nun selbst escapen müssen. Dies ist notwendig, wenn ein Sonderzeichen wie ein normaler Buchstabe interpretiert werden soll und nicht in seiner besonderen Bedeutung, welche die Suche beeinflusst. Folgende Sonderzeichen haben eine solche besondere Bedeutung in der QueryStringQuery-Syntax und müssen, wenn diese Bedeutung nicht gewünscht ist, escaped werden:
| Zeichen | Bedeutung |
|---|---|
| +<wort> | <wort> muss im Dokument vorkommen |
| -<wort> | <wort> darf im Dokument nicht vorkommen (nur wenn davor ein Leerzeichen steht) |
| <wort1> && <wort2> | Beide Worte müssen im Dokument vorkommen |
| <wort1> und <wort2> getrennt durch zwei Pipe-Symbole | Mindestens eines der beiden Worte muss im Dokument vorkommen |
| > x < x | Größer/ kleiner als …-Suche (funktioniert mit Zahlen oder mit Worten) |
| >= x <= x | Größer gleich/kleiner gleich als …-Suche (funktioniert sowohl mit Zahlen als auch mit Worten) |
| = | Allein keine Bedeutung, am Anfang der Zeile: Powersuche |
| {x TO y} | Bereichssuche (ohne x und y) |
| [x TO y] | Bereichssuche (inklusive x und y) |
| <wort>^ | Gewichtung des Wortes |
| "<wort> <wort>" | Phrasensuche |
| <wort>~ | Fuzziness (unscharfe Suche) |
| * | Wildcard, beliebig viele Zeichen |
| ? | Wildcard, exakte Anzahl an zu ersetzenden Zeichen |
| \ | Escaped-Zeichen |
| / | Keine Bedeutung |
| <feldname>:<wort> | Suche in <feldname> nach <wort> |
# Feldnamen
Einzelne Felder der Elasticsearch können direkt abgefragt werden, sofern der Feldname bekannt ist. Eine Übersicht über die Feldnamen wird von ELO nicht bereitgestellt. Die Administration kann sie jedoch über die REST-Schnittstelle der Elasticsearch abfragen:
http://<host>:<port>/<Name des Repositorys in Kleinbuchstaben>/_mapping?pretty
Weitere Informationen zur Interpretation der Abfrage bietet Elasticsearch unter diesem Link: https://www.elastic.co/guide/en/elasticsearch/reference/5.6/index.html (opens new window)
Beachten Sie
ELO behält es sich vor, die Feldnamen zwischen den Versionen zu ändern. Daher ist es möglich, dass eine Anfrage mit einer Version funktioniert, mit der nächsten Version jedoch nicht mehr.
# Beispiele für Abfragen
Oft ist es sinnvoll herauszufinden, ob ein bestimmtes Dokument über die iSearch auffindbar ist. Dies kann über folgende Suchanfrage herausgefunden werden:
=elo_id:<Objektid>
Voraussetzung für die Suche ist, dass Sie mit dem Recht Alle Einträge sehen, Berechtigungen ignorieren suchen. Falls dies zu keinem Ergebnis führt, ist das Dokument bisher nicht in die iSearch aufgenommen worden.
Die Suche nach ELO[123 führt zu einem Syntaxfehler, da die eckige Klammer ein Sonderzeichen ist, das auch mit der Standardsuche für eine Bereichssuche genutzt werden kann. Um trotzdem nach diesem Zeichen zu suchen, kann die Powersuche verwendet werden, indem folgende Abfrage gestellt wird:
=ELO\[123
# Lizenzbestimmungen bei der Verteilung von Serverprozessen
ELOprofessional-Systeme sind nur bedingt clusterfähig, sie erlauben ausschließlich den Hot-Standby-Betrieb der einzelnen Komponenten. ELOenterprise-Systeme sind dagegen voll clusterfähig.
Bei ELOprofessional dürfen die Serverprozesse nur innerhalb desselben Hosts, also auf einem Serversystem, verteilt werden. Bei ELOenterprise hingegen lassen sich die Prozesse auf mehrere Hosts (VMs oder physische Server) verteilen.
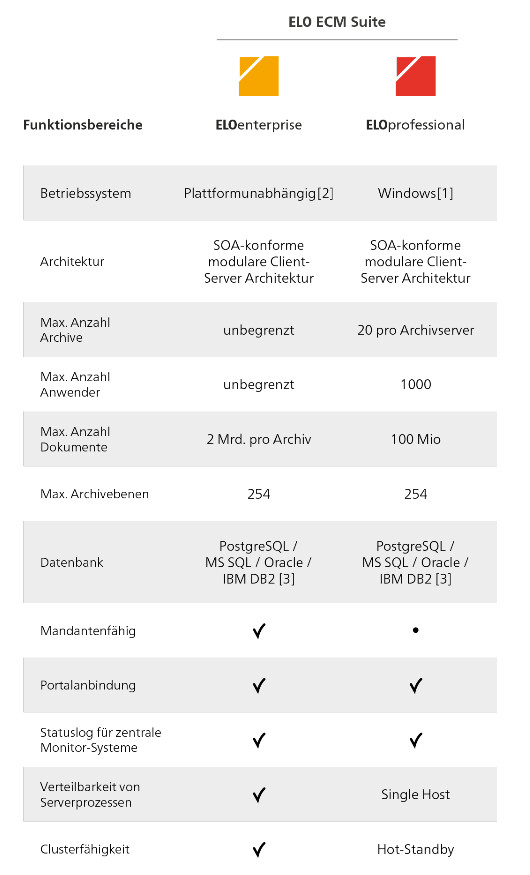
Im Rahmen von ELOprofessional können somit die ELO Serverkomponenten (z. B. ELO Automation Service (ELOas)) auf mehreren Tomcat-Servern verteilt werden, solange sich diese auf einem Serversystem (VM oder physischer Server) befinden. Bei ELOenterprise ist es hingegen erlaubt, die Tomcat-Server auf mehreren Serversystemen (VMs oder physischen Servern) zu installieren.