# Technical description
# Architecture
# Elasticsearch
Elasticsearch is a distributed, highly scalable open source search engine based on Apache Lucene that allows users to save large data volumes and perform extremely fast searches. Communication takes place via a RESTful web interface.
There is a great amount of reference material available online, including basic documentation and methods. This documentation only addresses the details relevant for use in the ELO system environment. For more information, we recommend the following starting point for further research: https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html (opens new window).
# Lucene
Elasticsearch uses Apache Lucene as its core library. With Elasticsearch, each index can be divided into several parts (referred to as shards). One shard corresponds to one Lucene index, which consists of one folder containing the associated index files.
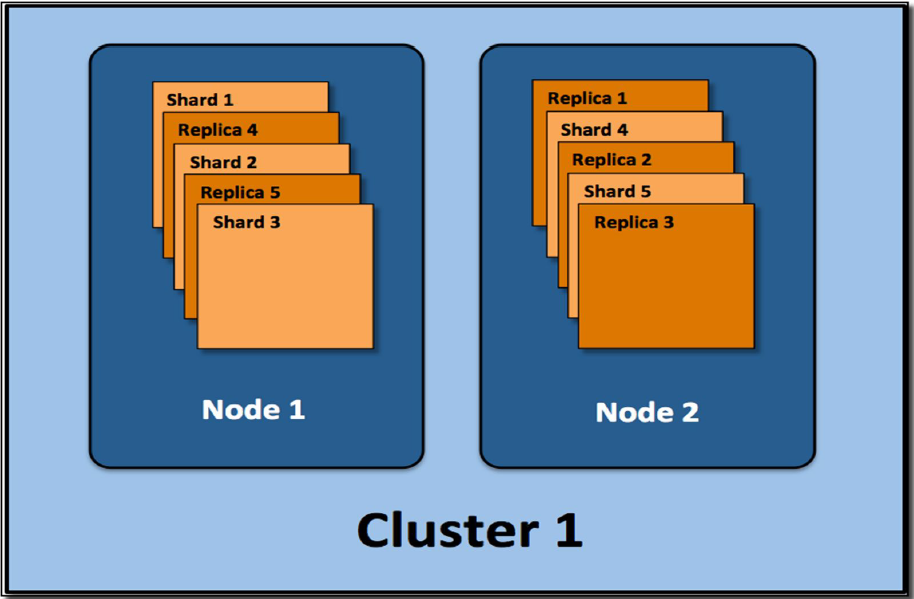
The shards can be distributed to multiple servers (nodes). You can also create replicas. These form a cluster.
# Language support
The Elasticsearch uses its own language analyzer during indexing and the search process. This optimizes language-specific search rules and patterns. For ELO specifically, please note that the repository language (selected during installation) has a major influence on the search.
The following languages are supported:
German, English, French, Spanish, Italian, Portuguese, Danish, Swedish, Polish, Dutch, Czech, Hungarian, Romanian, Turkish, Bulgarian, Finnish, Greek, Norwegian, and Russian.
# Processing with ELO
The following flowchart illustrates processing with ELO:

The ELO Indexserver transfers the data to Elasticsearch, which uses its own language analyzer during indexing and the search process. The index data is saved in Lucene indices.
Searching indexes requires access to:
- The index files
- A consistence Lucene database
- A functional Elasticsearch language analyzer
- A running ELO Indexserver (ELOix).
# Security
Since ELO ECM Suite 10.2, communication between the ELO Indexserver (ELOix) and Elasticsearch is encrypted (SSL). The Search Guard plug-in is used for this.
# Installation and upgrade
# ELO Server Setup
Installations or upgrades are done in the ELO Server Setup, which generates the configuration if it doesn't exist and installs the Elasticsearch program and the service, as well as a data directory where the index files are saved. The following options are available in the ELO Server Setup:
- Name of service
- Memory value
- Port
- Data directory

- With ELOenterprise, additional Elasticsearch servers (see also License terms when distributing server processes).
Please note
As of ELO 21.2, the ELO iSearch port (default: 9200) is secured with TLS/SSL.
You may get a certificate warning the first time you open it in a browser.
Depending on the browser and operating system, you must import the certificate into the certificate store of the browser or operating system. For example, if you are using Microsoft Edge or Google Chrome on Microsoft Windows, load the keystore.jks file from <ELO>\config\elastic\<ELO iSearch server>\certificates into the Windows certificate store. If you are using Mozilla Firefox, add the certificate to the Firefox certificate store by ignoring the certificate warning message.
# Checks after installation
After installation, you can call https://<server>:<port> (default port: 9200) with an administrative Tomcat account to perform some checks. If you use any browser, a JSON file is output, which you can open in an editor.
This allows you to view important basic data such as the version and name.
You can perform additional checks in the ELO iSearch configuration. You can reach the configuration via the Indexserver configuration page or the following link (log on with an administrative Tomcat account):
https://<server>:<ixport>ix-<REPOSITORY>/manager/esconfig/#/iSearchConfig
# Reindexing after upgrading from older ELO versions
Updating from an earlier ELO version (up to ELO version 23.6) to ELO version 25.0 or higher requires you to reindex the index data. The ELO Server Setup removes the previous Elasticsearch indexes as they are no longer compatible with the current Elasticsearch version.
During reindexing, first the existing index is deleted and then rebuilt. All fields are saved in both tokenized and not tokenized (as a phrase) forms meaning changes to this field setting do not require a reindex. In addition, the full text content is read out from the FT*.txt files generated in the ELO full text process and used for indexing.
You can initiate a reindex on the Indexer tab of the ELO iSearch configuration.
The progress is shown after you refresh the page.
# Background reindex
For upgrades from ELO version 9.3 and higher, the ELO Server Setup Upgrade Index function installs an isolated ELO Indexserver that builds the Elasticsearch index in the background. This makes sense for large systems in particular, as reindexing can take several days. You can use this function when updating to a more current ELO version or when making changes to the iSearch settings.

You can import this index when upgrading ELO so that the full scope of search functions is available immediately after the upgrade.
Refer to the Background reindex section for details of this process.
# Sizing and performance
A performant search is crucial for users to accept the ELO system. For this reason, the Elasticsearch must be optimized regularly (e.g. every six months, depending on the additional document and data volume) along with database performance. You should check whether this is necessary at the user level (by performing complex searches) but also at the server level (by occasionally analyzing the log file, see the section Log file).
# General information on sizing
Elasticsearch performance depends on the following factors:
- RAM both for the Elasticsearch JVM (Java Virtual Machine), additional Elasticsearch memory for caches, which is managed by the operating system, and for the operating system in general
- Number of processors/cores
- Memory technology/memory access times
The following general statements on sizing apply:
- RAM (see also the section RAM sizing):
- For small environments, the standard 4 GB + 4 GB of additional RAM suffice.
- You should allow approx. 24 GB (12 GB + 12 GB) for medium-sized environments (approx. 10 million documents).
- As there is a limit of around 30 GB per JVM for large environments, server clustering is recommended.
- Processors/cores:
- Each search requires a thread, i.e. a higher number of processors/cores achieves improved parallelization.
- Hard drives:
- Fast hard drives (SSD) significantly increase performance. We urgently recommend using SSD storage to run Elasticsearch.
Even for medium-sized environments, we recommend using ELOenterprise (see also License terms when distributing server processes).
# RAM sizing
With Elasticsearch, memory usage is not only related to the number and size of the documents. How the user works also plays a major role.
Generally, when it comes to memory usage, it is necessary to distinguish between the Java heap for the ELO iSearch service and the additionally required RAM for Elasticsearch. There is a clear recommendation to keep at least as much free memory available as is configured for the Java heap.
You configure a fixed Java heap in the ELO iSearch service, for example 10 GB, or initially 4 GB for a new ELO installation. There should then be as much free memory that isn't utilized by other applications or the operating system itself available to the operating system as a file cache system for Elasticsearch. This memory is used by the operating system as a file system cache and therefore by Elasticsearch. The main contents it contains are index data (fixed and temporary) and some types of caches for search queries.
By contrast, the Java heap contains the Elastic application itself, including a basic amount of memory per running shard (Lucene index) as well as the query cache and the field data cache.
For the initial size of the Java heap, you could use the following guideline value, which has to be adjusted later on depending on actual usage: basic amount 4 GB, plus as much as is currently needed (1 GB for 1 million ELO documents is a good starting value). Everything else is much more valuable as a file system cache. As an empirical value, the correct configuration of the Java heap is 8 to 16 GB for approx. 10 million documents. The exact value depends on actual usage and the type of index fields. If users in the ELO client frequently use filters for index fields that are marked as tokenized and context terms (i.e. filter values that can be selected for this field) can be shown and the index for this metadata form contains millions of documents, all potentially available field values are loaded to the Java heap and end up in the field data cache. This can cause the size of the cache and thus the required Java heap to grow significantly. This is also the case when sorting by this kind of field. If only aggregating to notTokenized fields or no filter suggestions are requested by users, this doesn't have an impact on the field data cache. Instead, the field contents land in temporary virtual files, which should be able to be found in the operating system file system cache mentioned above. This makes it difficult to predict how high the Java heap should be configured.
Please note
A separate Elasticsearch index is built for each metadata form. This requires a basic Java heap of approx. 50 MB (for a 1-node system without replicas). A large number of metadata forms therefore requires a large Java heap and thus a large amount of RAM for the ELO iSearch.
The recommendation is therefore: When configuring metadata forms, the number of forms used should not reach double-digits whenever possible. This applies for first generation and second generation metadata forms.
For the overall sizing of the Java heap and the remaining RAM as a file system cache, we recommend first determining the memory usage of all other applications on a system that are still running on the same computer or the VM, including the operating system. For example, an ELO Indexserver, ELO Textreader, and ELO OCR instance are still running there whose consumption isn't determined solely based on the configured memory, but that also requires a large file system cache. You can find the total amount for each application in your operating system's Task Manager application. Add the operating system usage to this. The total system RAM is made up of this value, the Java heap configured for Elasticsearch, and at least as much free memory as for the Elastic file system cache.
Example:
For example, the ELOix/ELOtr/ELOocr/operating system require 12 GB. ELO iSearch is configured for an 8 GB Java heap and requires another 8 GB for the file system cache on top of that. The total amount is therefore 12 GB + 8 GB + 8 GB = 28 GB. This would leave room for 4 GB in a 32 GB system. This isn't very much when the repository is growing.
In larger systems, we recommend running ELO iSearch on a separate VM or computer to prevent it from competing with other applications over the file system cache and forcing the operating system to outsource.
As a general rule: only as much Java heap as is needed, but as much file system cache as possible.
Information
We generally recommend setting the Java heap for ELO iSearch in the ELO Server Setup.
You also have the option to set the Java heap in the <ELO>\config\elastic\ELO-<instance_name>\jvm.options.d\ELO-\<instance_name>.options file in the ELO directory. After making changes to the configuration, you will have to restart the ELO iSearch. However, these changes will be lost the next time the ELO Server Setup is run, so this option is only suitable for test purposes.
For information on monitoring Java within ELO iSearch for analysis and support purposes, refer to the documentation ELO server > Maintenance and monitoring > Monitoring the Java environment > Server > ELO iSearch (opens new window).
# Optimizing the indexing process
You can only optimize the indexing process to a certain extent. The number of documents indexed at the same time is determined by the ELO Indexserver (ELOix). Based on experience, the index can handle about 2–3 million documents per day, including full text documents, in an optimized environment.
If the option Add to full text database (opens new window) is not enabled for an ELO document, the full text document is not generated, and is therefore not available for indexing. The re-indexing process can be accelerated if fewer full text documents exist. The size of the full text content also affects the indexing speed. Using maxFulltextContentMB in the Indexserver Configure Options (opens new window), you can set the maximum size of the full text content of a document that will be used for indexing. Documents containing only metadata without full text are re-indexed much faster.
# Optimizing search performance
Performance factors were already covered in the section General information on sizing. In large environments, increasing the number of shards per index can have a positive effect on the search speed if they are distributed to multiple nodes. Please note that changing the number of shards requires reindexing. Refer to the section Setting the number of shards per index for more information on configuring the number of shards.
# Disk space requirements for Elasticsearch indexes
The disk space required for Elasticsearch indexes depends on different factors, which can vary greatly in each customer repository. The main factors:
- Number of documents and folders
- Number and types of customer-specific and solution-specific fields in metadata forms (index fields)
- The volume of data contained for each field. The cardinality of the field plays a role. For gen. 1 metadata, multi-value behavior via the column index, for gen. 2 metadata the property whether the respective aspect mapping has the cardinality MANY (i.e. cardinality is MANDATORY_MANY or OPTIONAL_MANY).
- The setting whether full text is generated and indexed, share of full-text documents in the total number of documents, and the setting for the size limit of the full text to be indexed (maxFulltextContentMB)
- Starting with ELO version 25.1, the setting whether AI vectors are generated and indexed for the full text, as well as the size of the full text
- For Relation type metadata fields, (configurable) selected fields from the referenced document can be included in the referencing document
- For documents in a region (e.g. for documents below a business object), (configurable) selected fields from the region object can be included in the documents located in the region
As these factors vary greatly in each customer repository, it is not possible to make a sufficiently accurate estimate of the disk space requirements to be expected.
# Storage requirements for deleted documents
Documents marked as deleted in ELO are still counted as regular documents in the ELO iSearch. They must be searchable and retrievable via the API when the client performs a search with the option for including deleted documents or only deleted documents. Therefore, documents marked as deleted continue to occupy space in Elasticsearch caches, including the Java heap and the file system cache (RAM). In terms of disk space usage, they are still fully counted as regular documents.
In contrast, permanently deleted documents cannot be searched or retrieved. They no longer occupy space in the Java heap or file system cache (RAM). However, they still take up disk space in the index, because Elasticsearch/Lucene marks them as deleted according to internal rules and may remove them gradually during segment merge operations. In contrast, when a re-index occurs, all indexes are deleted, and with them, all documents in ELO iSearch.
# Operation
There are two important aspects to consider when operating Elasticsearch:
- Log files and their content
- Creating evaluations
# Log file
By default, the Elasticsearch log files are stored in the ELO installation directory within the logs folder.
Here, the ELO.log file is relevant (or ELO-<date>.log for older log files).
In individual cases, it may make sense to look at the Indexserver log file (ix-<repository>.log). For ELO 11 and ELO 12, you can search for the term queryTerm in the log file, for example. The following example shows the output of a full text search for the term test:
22:51:34,723 eloix-find-40 eloix-find-40 INFO (ElasticClient.java:183) - find(searchId=[(09A4500F-6BC6-4ECF-EFD6-A9E6B78C5A91)], queryTerm=Test, sort=IDATE\_DESC, highlightedText=false, resultField=true, relevance=true, currentFolderId=0, searchIn=2)
# Evaluations
You can query various Elasticsearch statuses via the browser. You can then use these for monitoring solutions (e.g. Nagios) if desired. You require an administrative Tomcat account to log on. A query outputs a JSON file like the one shown in the following screenshot, which you can show in Mozilla Firefox.
The URL for the health check is: https://<server>:9200/_cluster/health?pretty=true
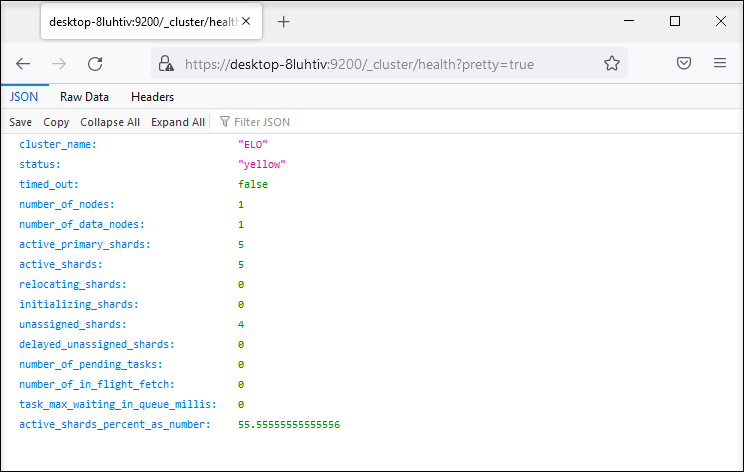
The status yellow means that the index is functional but the replica shards are not all available. In a single server environment using (1) as the default setting for replicas, the yellow status is normal.
The URL for the index directory name is: https://<server>:<port>/_cat/indices
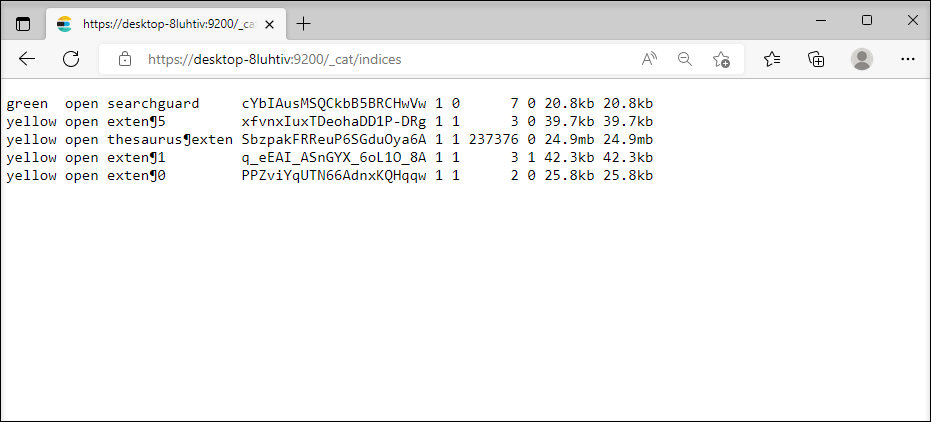
One index exists for each metadata form, and can be recognized based on its ID.
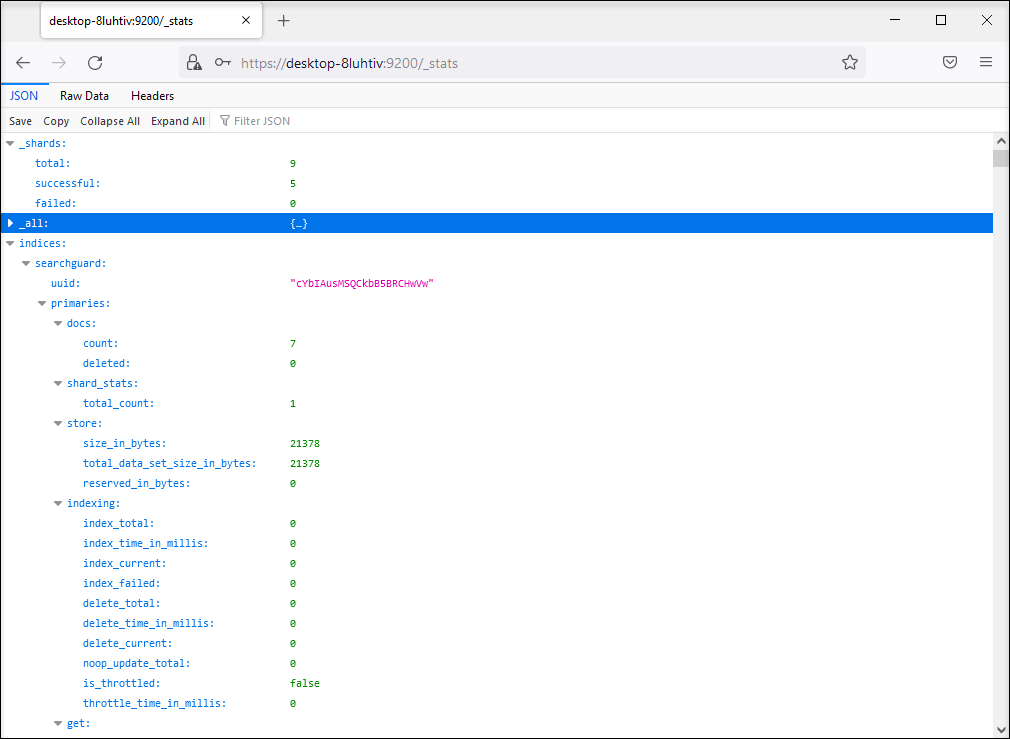
The URL for statistical data is: https://\<server\>:9200/_stats.
This allows you to check whether a new document has been added to the index. After a new document has been added, the value in the first line of the query after count is increased by 1.
Additional queries are possible in the same fashion. These are described in the Elasticsearch online documentation.
# Backup options and strategies
The iSearch data can be restored fully from the database via the Indexserver. The decision whether to create a backup of the Elasticsearch index depends on the following factors:
- How much downtime is acceptable for users?
Keeping downtime to a minimum requires a backup strategy that allows a backed up iSearch index to quickly be imported to a live system.
- How long will it take to restore the iSearch index?
The duration of the initial reindex can be used as an indicator of how long subsequent reindexes will take. You have to decide whether this downtime period is within reason for users.
There are two options for creating a backup. For both solutions, the indices between the different Indexserver versions may not necessarily be compatible. After importing the backup, you will have to reindex the documents changed since the backup was created. This can be done using the Updater.
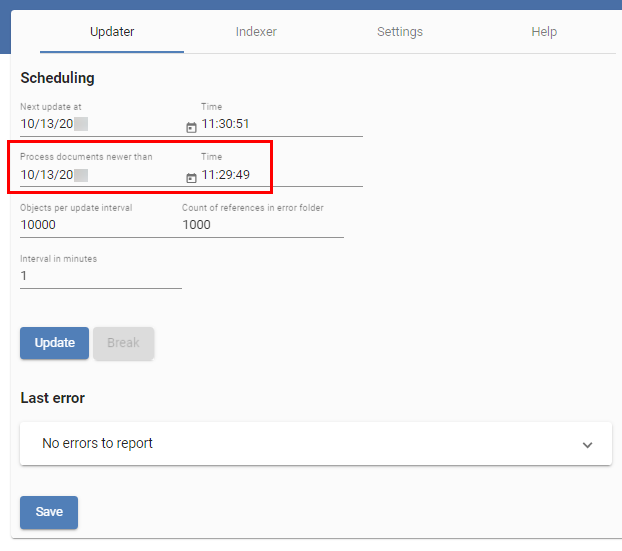
The value for Process documents newer than is set to the time the backup was created. It makes sense to create a backup once a day or week to keep the process for indexing changed documents to a minimum.
Please note that the index named searchguard is necessary to ensure SSL encryption by means of the Search Guard plug-in. If this index does not exist, you the Indexserver will not be able to connect to Elasticsearch. If you have accidentally deleted the searchguard index, you can restore it by running the server setup again. The searchguard index also depends on the selected administrative Tomcat account, meaning you cannot just copy the index if the account or passwords differ, and the index must be created by the server setup.
# Copying an existing index
You can copy the existing index from the file system and re-import it at a later point in time. Copy the entire folder located at <installation directory>/data/<…><server name>/index as a backup. If the backup is required, replace the content of the folder named above with the backup.
Before copying, you should stop the iSearch service to prevent access errors.
# Creating snapshots with Elasticsearch
Elasticsearch offers the option to create snapshots of existing indexes. If snapshots are generated regularly, a complete copy is not created every time. Instead, only the changed files are saved to reduce the amount of memory required.
You will find a guide here:
Please note
To recover a snapshot, the following line has to be inserted in the Elasticsearch configuration file (<installation directory>/config/elastic/<server name>/elasticsearch.yml): searchguard.enable_snapshot_restore_privilege: true
# Tips and tricks
# ELO iSearch configuration
You can open the ELO iSearch Configuration page, available starting with ELO 11, via the Indexserver configuration page or at the following link:
https://<server>:<Port>:/ix-<Repository>/manager/esconfig/#/isearchConfig
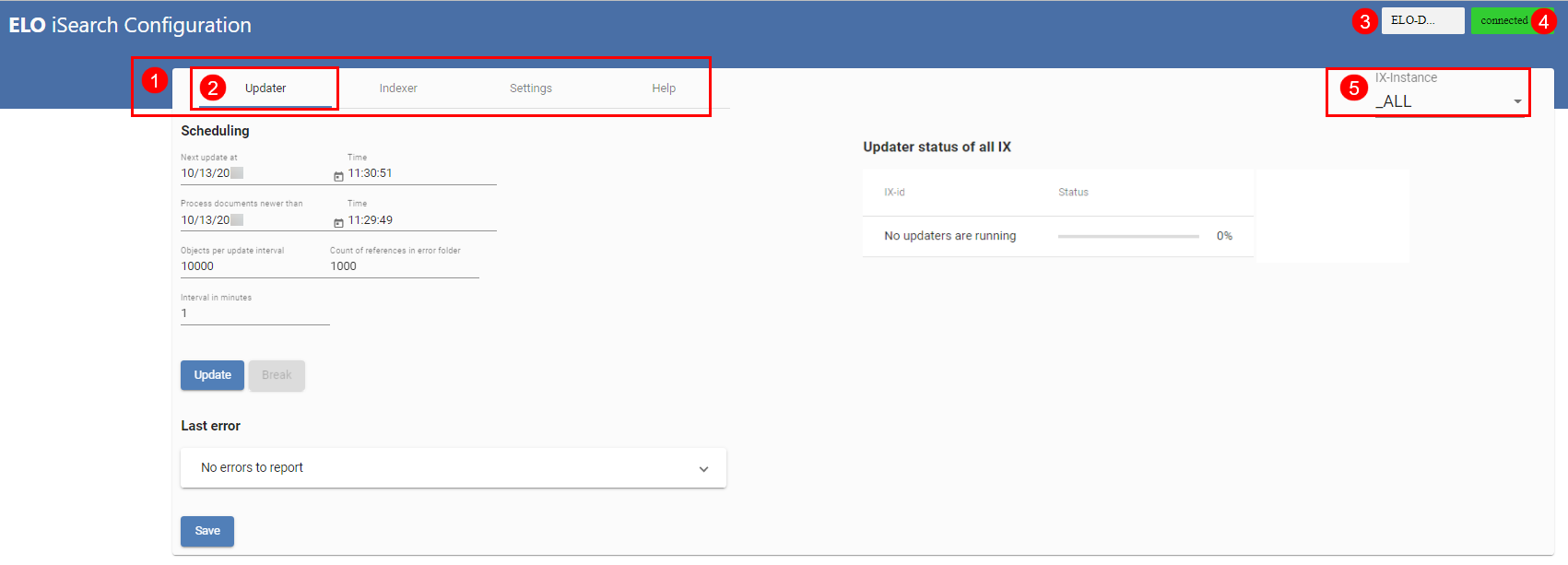
The above figure shows the ELO iSearch configuration. In the ELO iSearch configuration, you can access the different functions of the iSearch (1); the active tab is underlined in blue (2). At the top right (3) you will see the name of the ELOix instance calling the ELO iSearch configuration, with the connection status to ELO iSearch (4) either connected or disconnected.
Since ELO 11, the settings for ELO iSearch are saved in the eloixopt table specific to the instance or for all instances (_ALL), as with the Indexserver options. In the table, all the ELO iSearch settings have the prefix esearch. In the ELO iSearch configuration, you can view and edit the settings for all instances (_ALL) or specific instances (5).
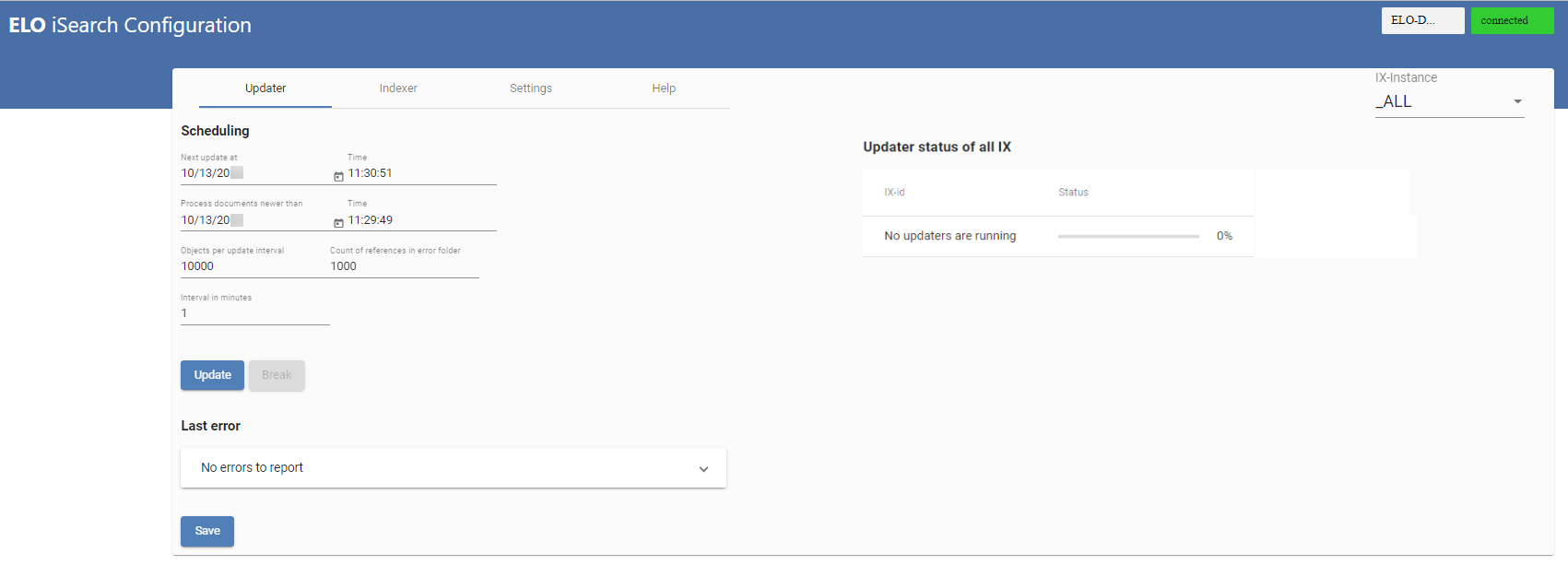
# Updater
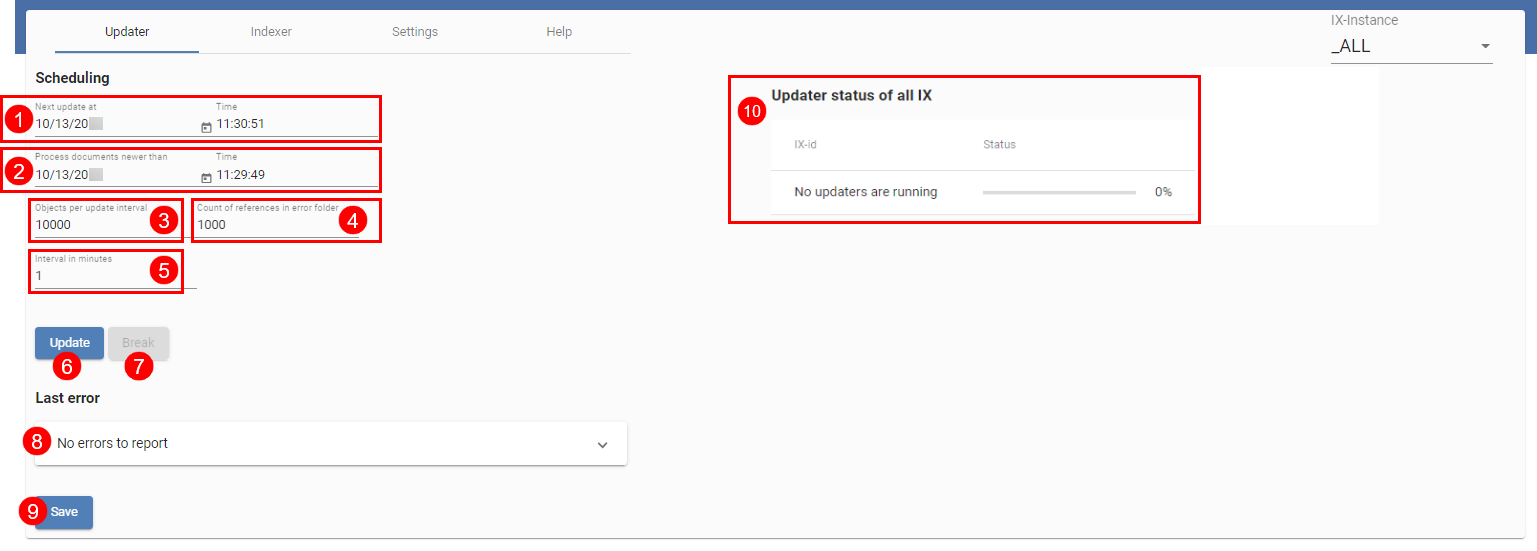
The above figure shows an overview of the Updater. This is required to regularly update ELO iSearch. It also ensures new and changed objects are sent to ELO iSearch. In the top line (1), you will see when the Updater is scheduled to start again, and the next line (2) indicates from which date on documents are processed. You can set both values. In the default configuration, the Updater runs every minute (5) and processes a maximum of 1000 objects (3) in the smallest time unit (1 minute). Please note that the number of selected objects is cached in the ELOix memory, so you should only change this value with caution.
If there are issues indexing a document, a reference to the document is created at the following path in ELO:
Administration//Fulltext Configuration//Update Errors
This allows you to easily monitor errors and make sure that documents are sent to ELO iSearch again, for example by opening the Metadata dialog box. You can set the maximum number of documents in this folder in (4). If you set 0, no references will be created.
Save any changes with the Save button (9).
Updater status of all IX (10) provides an overview of all running update processes. You can also manually start the update process by clicking Update (6) or pause by selecting Break (7). Note that starting and stopping always applies to the current ELOix instance.
The most recent error in the update process is shown in Last Error (8).
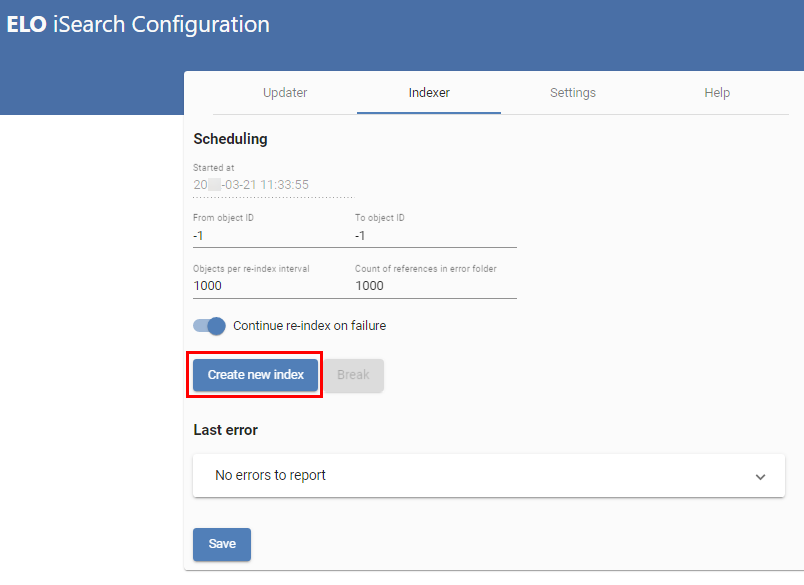
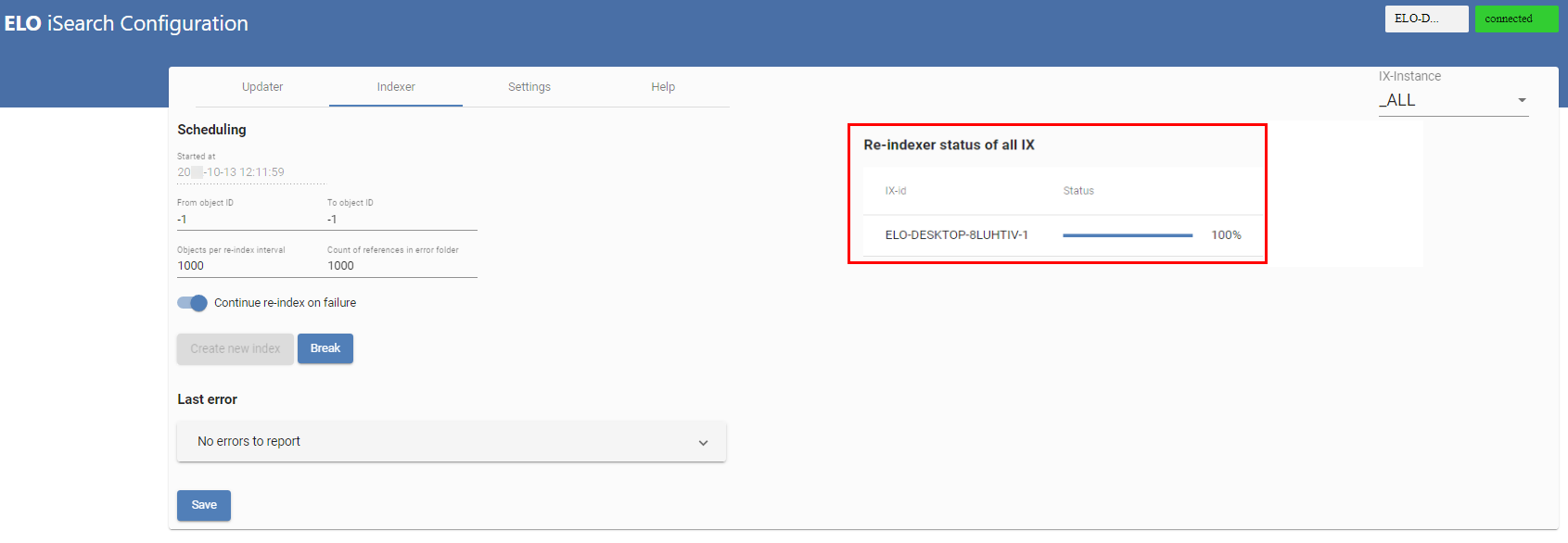
# Indexer
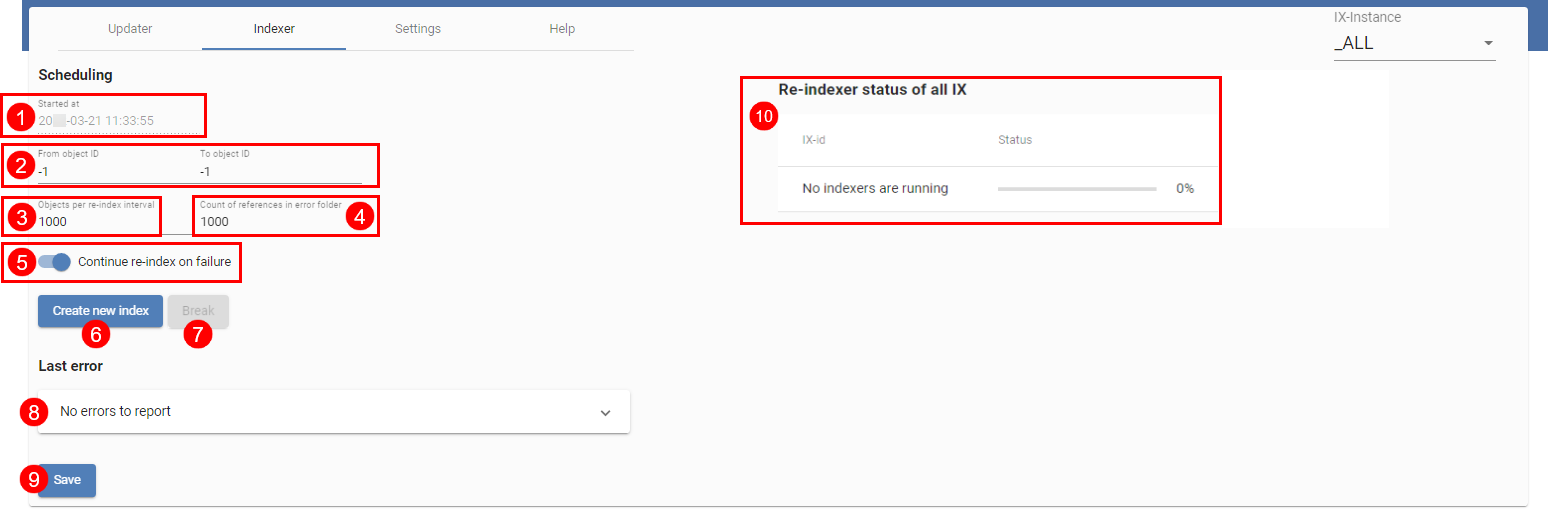
The Indexer (image above) initially provides ELO iSearch with objects from ELO. All existing objects are sent to ELO iSearch, beginning with objects with the highest ID, indexed in descending order. As a result, new objects can be found first, provided the index is used in the productive environment right away.
The top line (1) indicates the start time of the last reindex process. In (2) and (3), you can choose the object IDs to be indexed. If you would like to perform a complete reindex, set both values to -1. The existing index is deleted as a result. If you would like to add only specific objects to an existing index, you can do this by means of IDs.
The settings for the objects per index interval (3) and references in ELO (4) correspond to those of the Updater. The references are filed to the folder at the following path:
Administration//Fulltext Configuration//Reindex Errors
This value is the same for both the Updater and the Indexer.
The Continue Reindex on Failure setting (5) indicates whether to cancel or continue reindexing in case of an error. If you would like to continue, you should regularly check the log outputs.
The most recent error in the reindex process is shown in Last Error (8).
Select Save (9) to save the settings.
You can start a reindex (if both object IDs are set to -1), or continue (6) or cancel it (7). As with the Updater, remember that this always applies to the ELOix instance the configuration page was called with.
(10) provides an overview of all active reindex processes.
# Settings
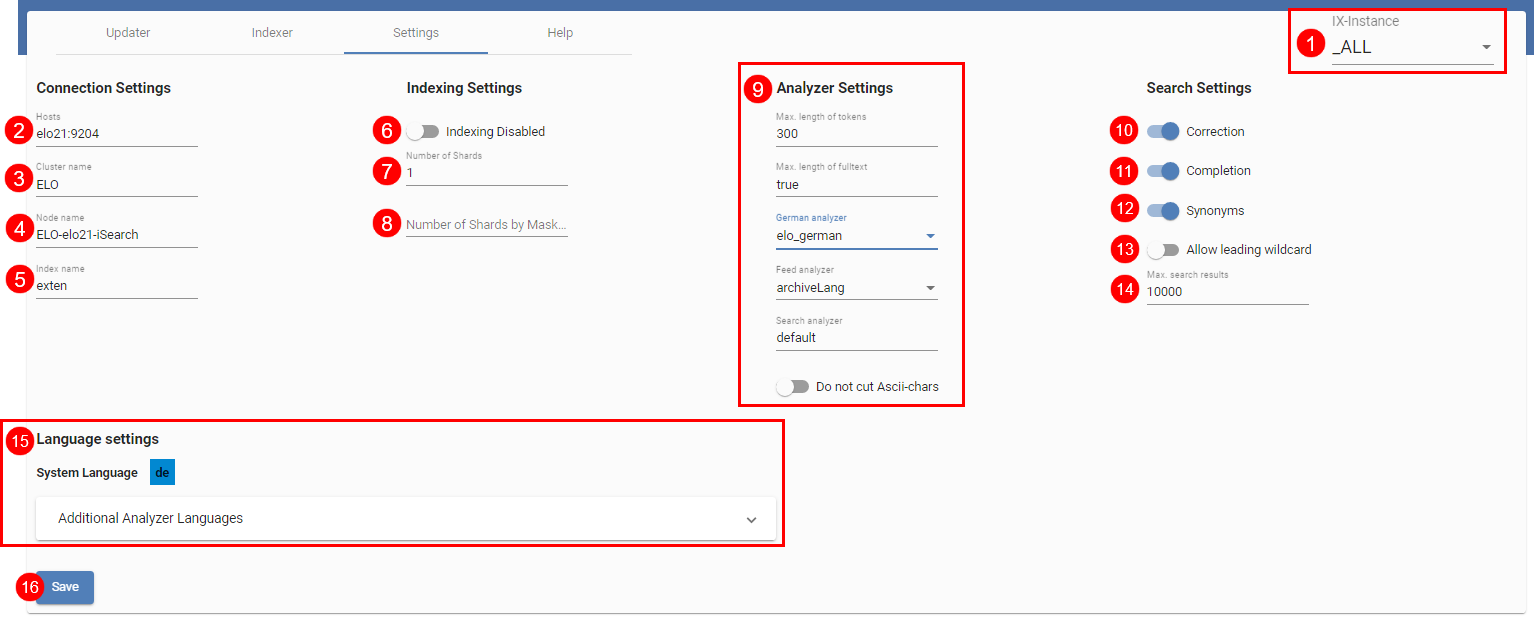
The above image contains an overview of additional setting options for ELO iSearch. In IX instance (1), select whether the settings should be applied to all instances or to a specific instance (see also the next figure ELO iSearch configuration, ‘Setting' tab, instance-specific settings).
Details on the connection between ELOix and Elasticsearch are specified in (2), (3), and (4). The name of the Elasticsearch index (5) corresponds to the name of the repository in lower case letters by default.
You can also specify whether an ELOix should be used to send objects to ELO iSearch at all (6). If this setting is enabled, the full text search via ELO iSearch is still enabled.
The number of shards and shards per form is set under (7) and (8). Th chapter Setting the number of shards per index describes these settings in more detail.
The Analyzer settings (9) determine how text sent to Elastic search is processed. Normally, you can use the default settings.
Settings (10) to (14) apply to the search. You can set whether to return suggestions for corrections (10) or synonyms (12) for the search query and whether autocomplete (11) is active. Furthermore, you can enable searches with a wildcard character at the beginning of the term (13). This is disabled by default, as searches with a leading wildcard can cause high load on the server. You can also set the maximum search results (14) returned via the findFirstSords() and findNextSords() ELOix API calls.
You can edit the ELO iSearch language settings under Language Settings (15). The system or repository language is set by the ELO Server Setup and cannot be changed. You can select additional languages depending on the available licenses. During indexing, the languages configured determine whether special language-specific Analyzer steps are used for token generation for a document with a recognized language. For example, a decompounder filter can be used for the language German to break down compound words. As a result, non-compound subwords may also be found. For the language English, typical stop words can be removed. If a language is recognized for a document during indexing that is not included in the configured languages, the document is still indexed, but only with the Analyzer steps that are not language-specific (fallback Analyzer).
Select Save (16) to save all settings. Please note that the settings (5), (7), (8), (9), and (15) require a reindex to apply to all data and not cause inconsistent data in ELO iSearch.
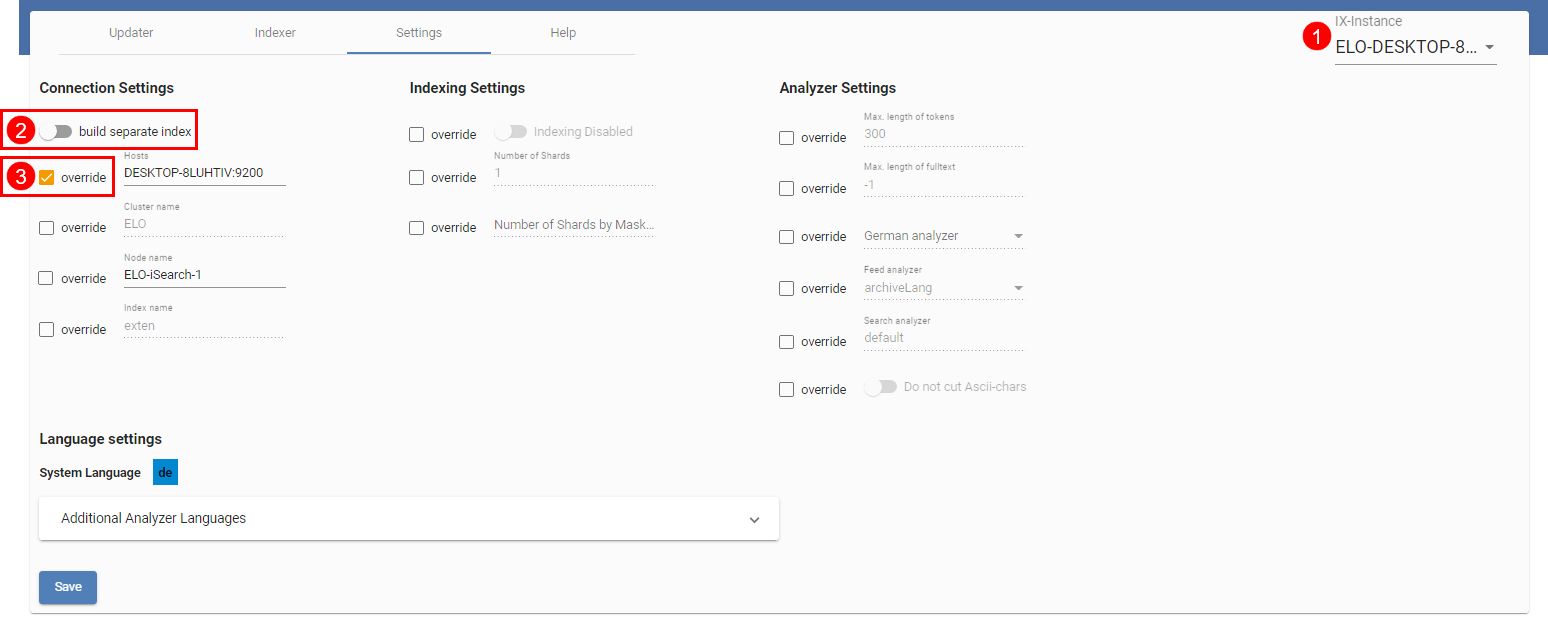
The figure shows the setting page for the instance ELO-DESKTOP-8LUHTIV (1). All settings where the override check box is enabled (3) overwrite the settings applied for all instances.
You can only apply the build separate index (2) setting for specific instances. If this setting is enabled, a separate index is built with this Indexserver if either the connection settings or the index name differs from those of the other instances. This is explained in more detail in the chapter Background reindex.
# Elasticsearch service configuration
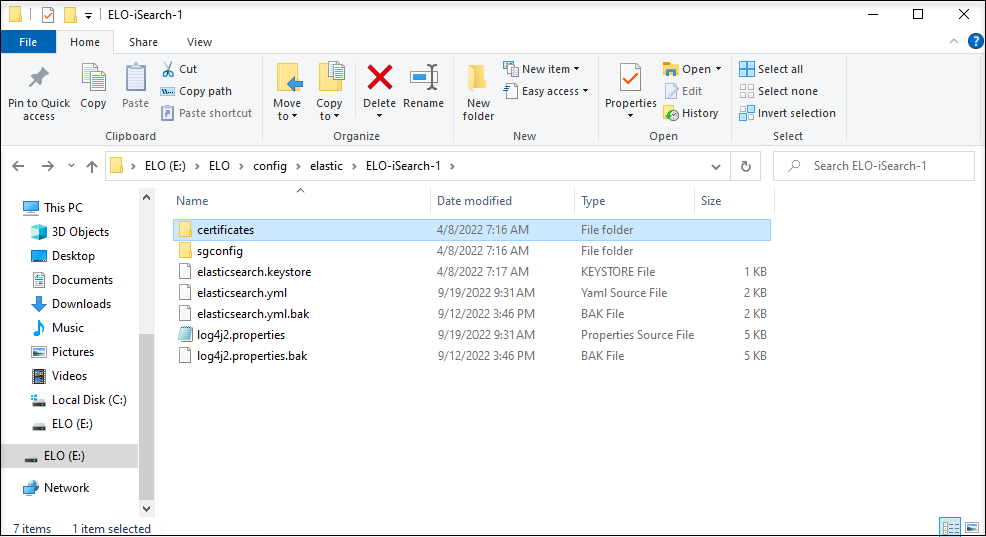
The Elasticsearch service is configured via multiple files and directories.
In detail, the files and directories contain the following:
elasticsearch.yml: Central configuration file for Elasticsearch. Refer to the following website for more detailed information: https://www.elastic.co/guide/en/elasticsearch/reference/current/important-settings.html (opens new window)
Please note
Do not add any options to the elasticsearch.yml configuration file unless asked to do so by ELO Support.
log4j.properties: logging settings
sgconfig: directory containing the Search Guard plug-in configuration
certificates: keystore and truststore for SSL communication with ELO Indexserver
# SSL communication
Starting with ELO ECM Suite 10.2, communication between ELO Indexserver instances and Elasticsearch is encrypted. The ELO Server Setup creates self-signed certificates as well as corresponding keystores and truststores during installation. The keystore and truststore are created within the respective config directories (Indexserver and Elasticsearch) and can be opened with the standard Java tools (e.g. keytool.exe) to check the certificates. Enter the password for the administrative Tomcat account.
# Indexserver plug-ins
Since ELO 11, ELO Indexserver can be extended using OSGi plug-ins. For example, the Elasticsearch interface is located in this type of plug-in. In the future, this distribution will enable access to a newer Elasticsearch index with an older version of the ELO Indexserver. One plug-in directory is configured for each Indexserver.
# Setting the number of shards per index
Starting with ELO 11, one index is created per metadata form. By default, each index consists of one shard. Creating one index per metadata form alone boosts cluster performance, as the indices are distributed to several nodes.
It also makes sense to split large indices into several shards. The advantage of this is that search queries are run in parallel on all shards. However, the number of search queries run in parallel within a node does not exceed the number of available processors.
As a result, the number of shards is based on the data contained. Elasticsearch recommends keeping the shard size between 20GB and 40GB. Too small of shards results in excessive communication between the shards, as the data has to be synchronized between them. Metadata forms containing an excessive amount of sords with full text should be split into multiple shards whenever possible.
The number of shards per metadata form can be set on the ELO iSearch configuration page, but changing this number requires all data to be reindexed.
# Setting the number of replicas per index
Replicas are like copies of an index. You can choose any value, including 0. One primary shard is created for each shard, as well as the specified number of replica shards in the cluster. Primary shards and replica shards are always created on different nodes to be able to continue providing data in case of a failure. If a node fails, the primary shards that were previously allocated to this node are allocated to a different node. The replica shards are distributed to other nodes to ensure the best possible system reliability and performance.
Another advantage of replica shards is parallel search queries: Elasticsearch distributes search queries to different primary shards and replica shards in order to balance the load of the search queries.
The health status of an index depends on what shard are available: If the primary shard is available, the status is yellow. If all replica shards are also available, the status is green.
The number of replica shards should be adjusted to the number of nodes in the cluster so that the shards can be distributed to several nodes in order to ensure system reliability. On the other hand, each replica requires just as much memory as the primary shard.
The default setting for the number of replicas is 1. In a cluster of more than one instance, each shard is replicated once, meaning it exists twice in total. Changing the number of replicas does not require reindexing.
To speed up reindexing in a cluster, you can set the number of replicas to 0 for the duration of reindexing and then increase it once reindexing is complete. If the number of replicas > 0, the data in both the primary shard and each replica shard is indexed at the same time. This means that analysis and conversion to Elasticsearch data takes place several times in parallel. If the number of replicas is set to 0, the data is only processed in one node during reindexing. Once the number of replicas is increased, the indexed primary shards are copied to the other nodes, which is generally much faster. Of course, system reliability cannot be guaranteed during reindexing.
The setting applies to an index and can be changed to 2 (opens new window) as in the following metadata form with ID 42 in the repository, for example with the curl tool (https://curl.haxx.se/):
curl -X PUT "localhost:9200/repository¶42/_settings" -H 'Content-Type: application/json' -d'
{
"index" : {
"number_of_replicas" : 2
}
}
'
If you'd like to change the setting for all indices, do not specify an index and use the URL the localhost:9200/_settings.
# Tokenization
The Disable tokenization option for a field template disables the search rules and patterns for this field. The exact values in the metadata appear in the filter list. For this field, the search also works with exact values. In this case, partial terms are not taken into account.

When search rules and patterns are enabled, the filter list only contains individual words – both the original words as well as their root forms. The search options in this filter correspond to those of the search input field.
# Integrating custom thesauruses
You can customize the thesauruses that ELO iSearch uses for a repository. The necessary files are located at the following path in ELO:
Administration//Fulltext Configuration//Thesaurus
This path contains a country-coded child directory containing three documents for each language.

<Language>_thesaurus: The thesaurus supplied by ELO for this language. You shouldn't change this file so that it can be replaced with a newer version when performing an update.
<\Language>_add: In this document, you can enter terms to be added to the thesaurus as synonyms.
<Language>_stop: With this document, you can exclude specific terms from the thesaurus that do not fit your application.
Please note
After these documents are changed, the ELO Indexserver has to be restarted so that the thesaurus can be rebuilt based on the changed files.
# Cluster operation
You can read about how to run ELO in a cluster in the documentation on ELO iSearch under ELO server – Installation and operation (opens new window).
# Recommendations in case of error messages
# Error message containing 'pending translog recovery'
After an unplanned restart of the ELO iSearch service, the iSearch log may contain error messages with the text pending translog recovery.
Example:
[2023-06-29T13:22:51,662][WARN ][o.e.i.f.SyncedFlushService] [ELO-iSearch] failed to flush shard [contelo¶2][0], node[8NAibzRYQtqFpTY_Fl7mug], [P], recovery_source[existing store recovery; bootstrap_history_uuid=false], s[INITIALIZING], a[id=o1RcLpTjTdWLSNrMOnzlGA], unassigned_info[[reason=CLUSTER_RECOVERED], at[2023-06-29T11:05:49.208Z], delayed=false, allocation_status[deciders_throttled]] on inactive
java.lang.IllegalStateException: [contelo¶2][0] flushes are disabled - pending translog recovery
at org.elasticsearch.index.engine.InternalEngine.ensureCanFlush(InternalEngine.java:2572) ~[elasticsearch-7.15.2.jar:7.15.2]
There may be a lot of these messages and they might appear when ELO iSearch is closed and didn't manage to transfer all transactions to the index before shutting down (e.g. if there wasn't enough RAM or the hard disk was full). On bootup, Elasticsearch then attempts to transfer the Translog file to the index. With a high volume of data, this can take an hour or possibly even several hours. The indexes are not available during this time.
Recommendation:
First, you have to wait until the entire Translog has been transferred to the index and these messages no longer appear. Next, you should check what the original problem was that caused the ELO iSearch service to shut down.
Avoid starting re-indexing via the ELO iSearch configuration page while these messages are appearing. Generally, the index is consistent again once Translog recovery is completed and so re-indexing is not necessary.
If the system is forced to shut down during Translog recovery, this may result in permanently corrupt index data that can no longer be fixed with Translog recovery. As a result, re-indexing must be performed or a fresh install of the ELO iSearch may even be necessary.
# Reindexing terminated due to too many feed posts
In rare cases, the iSearch reindexing process may be terminated due to an extremely large number of feed posts. This can be caused by malfunctioning automated processes, such as import routines or scripts that store documents and inadvertently generate a large number of feed posts, sometimes even with error messages as content.
This can be observed in two places:
The ELO Indexserver crashes with the error message:
java.lang.OutOfMemoryError: Java heap space.The ELO Indexserver log indicates SQL exceptions with
read timed outin relation to the feedaction table. Additionally, logs may show documents associated with an unusually high number of feed posts.Example:
19:20:58.529 INFO esin-8 esin-8 (FeedIndexer.java:108) - [821022] indexFeed=true: posts=#145239
To determine whether too many feed posts are the cause of the termination, you can use a query in the database to find out which SORDs (i.e., ELO documents) have a very high number of feed posts.
Example of an SQL query:
select count(*), objid
from documentfeed d
inner join feedaction f on d.feedguid=f.feedguid
inner join objekte o on d.objguid = o.objguid
group by objid
having count(f.feedguid) > 1000
order by 1 desc
The number 1000 is provided as an example threshold for the number of feed posts per ELO document. If very high values (tens of thousands or millions) appear in the first results column, the cause of these feed entries must be identified, and any malfunctioning automated processes corrected.
Information
In small ELO systems, even a total of several million feed entries can cause an increased load or higher memory usage on the ELO Indexserver. The total number of entries in the feedaction table is relevant in this case.
After correcting malfunctioning automatic processes, restore the system to a working state as follows.
Method
- First, back up the database.
- Stop all ELOix instances while performing the corrections.
- Identify the feedguid for the relevant objguid in the documentfeed table.
- In the feedaction table, delete the rows with the feedguid that are no longer needed or are incorrect.
- Optional: Identify the corresponding actionguids for the determined feedguid in the feedactionhist table (change history) and then delete the rows matching these actionguids in the feedactionhist table. These do not directly affect reindexing, but are superfluous if the main entries have been deleted.
- If all associated rows in the feedaction table have been deleted (i.e., if all these feed posts are incorrect or unnecessary), delete the row with this feedguid (feedaction.feedguid = documentfeed.feedguid) in the documentfeed table.
Alternative:
If only old or unnecessary feed posts need to be deleted, it is sufficient to perform steps 1 to 6, skipping step 3. For example, all entries that are still needed can be copied to an additional table and then renamed in feedaction.
# Power search
The ELO iSearch power search enables users to send complex search queries to ELO iSearch and use the iSearch syntax.
The power search function in ELO iSearch allows you to access the underlying Elasticsearch database. As a result, users can directly access fields that they cannot select using a filter as well as use the Elasticsearch syntax to run complex search queries.
The ability to access internal structures is also the downside of the power search given that the syntax is highly technical and requires knowledge of the internal data structures. It should also be noted that these internal structures can change in future versions of ELO, meaning that existing search requests may no longer work or no longer work properly.
Important
You should only use the power search in exceptions, i.e. if a normal search query will not achieve the desired result, such as with certain administrative requests.
# Using the power search
You can use the power search in the ELO Java Client as well as in the ELO Web Client. Starting with an equal character (=), enter the search query in the field provided as shown in the example below.

The power search sends requests straight to the Elasticsearch via the ELO Indexserver. The ELO Indexserver carries out an authorization check to ensure that you only see the documents that you have permissions to even when running the power search.
The power search syntax corresponds to the syntax QueryStringQuery, as documented by Elasticsearch:
It is especially important that you are able to escape special characters. This is necessary if the user wants the character to be interpreted as a normal letter in order to ignore any special meaning in the context in which they are being used, which would affect the search. The following characters have a special meaning in the syntax QueryStringQuery and must therefore be escaped if this meaning is to be ignored:
| Characters | Meaning |
|---|---|
| +<word> | <word> must occur in the document |
| -<word> | <word> must not occur in the document (unless a space precedes it) |
| <word1> && <word2> | The document must contain both words |
| <word1> and <word2> separated by two pipe symbols | The document must contain at least one of the two words |
| > x < x | Greater/less than (works for numbers or words) |
| >= x <= x | Greater than or equal to/less than or equal to (works for numbers as well as words) |
| = | Has no significance on its own, at the beginning of the line: power search |
| {x TO y} | Range search (without x and y) |
| [x TO y] | Range search (including x and y) |
| <word>^ | Significance of word |
| "<word> <word>" | Phrase search |
| <word>~ | Fuzziness (fuzzy search) |
| * | Wildcard, any number of characters |
| ? | Wildcard, exact number of characters to replace |
| \ | Escape character |
| / | No meaning |
| <field name>:<word> | Search <field name> for <word> |
# Field names
It is possible to query Elasticsearch fields directly provided that the user knows the name of the field. ELO does not provide a list of the field names, but administrators can request them via the Elasticsearch REST interface.
http://<host>:<port>/<repository name in lowercase>/_mapping?pretty
Elasticsearch provides more information on interpreting requests here: https://www.elastic.co/guide/en/elasticsearch/reference/5.6/index.html (opens new window)
Please note
ELO reserves the right to change the names of fields in between versions. It is therefore possible that a search query will work with one version, but not with the next.
# Examples of requests
It often makes sense to find out whether a document can be found using the iSearch. You can do so using the following search query:
=elo_id:<object_id>
To perform the search query, you need the right View all entries, ignore permissions. If the search does not come up with the correct results, the document has not be added to the iSearch.
The search for ELO[123 leads to a syntax error since the square bracket is a special character that can normally be used for a range search. You can still search for this character by issuing the following request in the power search:
=ELO\[123
# License terms when distributing service processes
ELOprofessional systems are only cluster-ready to a certain extent. They only allow for hot standby operation of individual components. ELOenterprise systems, however, are fully cluster-ready.
With ELOprofessional, server processes may only be distributed within the same host, i.e. on a server system. In contrast, with ELOenterprise processes can be distributed across multiple hosts (VMs or physical servers).
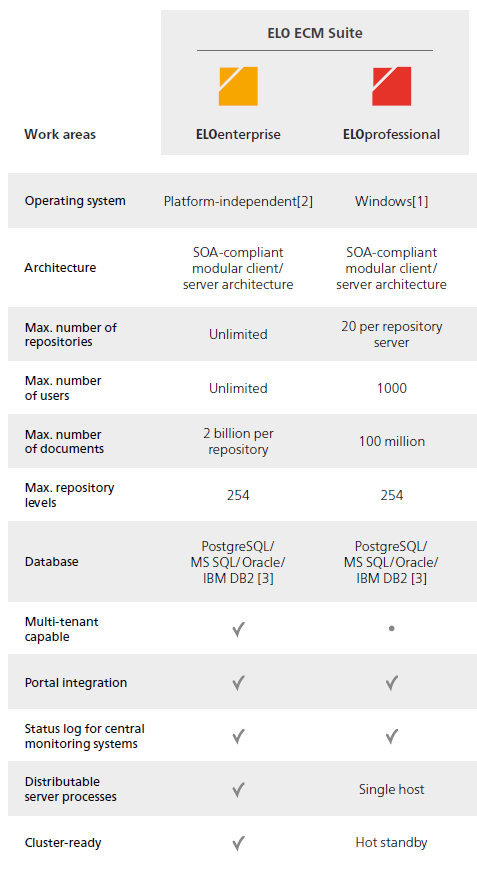
With ELOprofessional, the ELO server components (e.g. ELO Automation Services (ELOas)) can be distributed across multiple Tomcat servers as long as they are located on one server system (VM or physical server). In contrast, with ELOenterprise, Tomcat servers can be installed on multiple server systems (VMs or physical servers).