# Description technique
# Architecture
# Elasticsearch
Elasticsearch est un moteur de recherche Open Source sur la base de Apache Lucene. Elasticsearch permet d'enregistrer un volume important de données et de les parcourir rapidement. La communication se fait par le biais d'une interface Web RESTful.
Sur Internet, vous trouverez de nombreux documents et informations à ce sujet. Dans cette documentation, nous abordons surtout les détails qui sont importants pour une mise en place dans un système ELO. Pour tout complément d'information, nous vous recommandons de consulter le site suivant : https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html (opens new window).
# Lucene
Elasticsearch utilise Apache Lucene en tant que core library. Avec Elasticsearch, chaque index peut être divisé en plusieurs parties (Shards). Un shard correspond à un index Lucene. Celui-ci se compose d'un classeur avec les fichiers d'index correspondants.
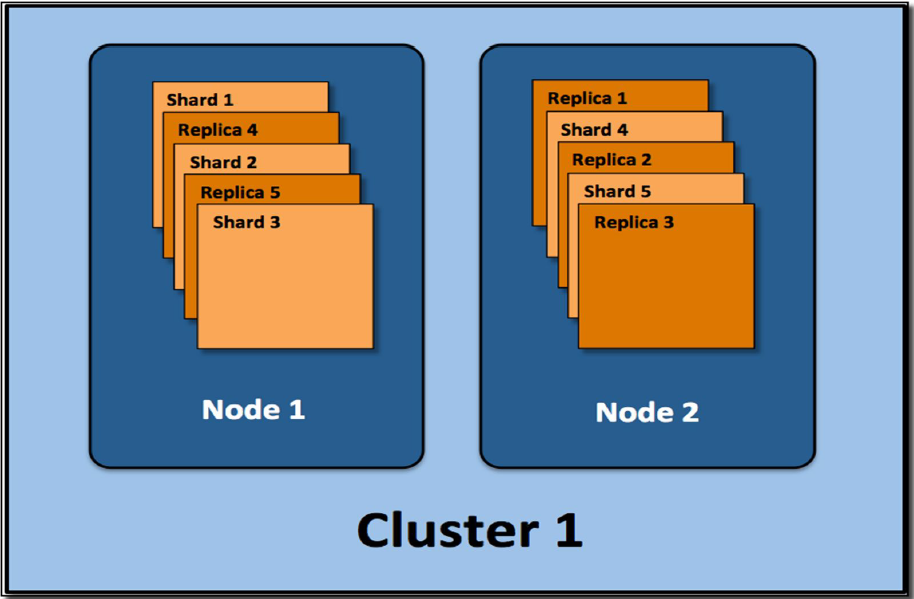
Les shards peuvent être répartis sur plusieurs serveurs (Nodes). Il est possible de créer des replicas. Le résultat est un cluster.
# Analyse linguistique
Elasticsearch effectue une propre analyse linguistique aussi bien lors de l'indexation que lors de la recherche. Cela permet d'optimiser les règles de recherche spécifiques. Il est important de souligner que la langue de l'archive (sélection lors de l'installation) a une influence considérable sur la recherche.
Les langues suivantes sont supportées :
allemand, anglais, français, espagnol, italien, portugais, danois, suédois, polonais, néerlandais, tchèque, hongrois, roumain, turque, bulgare, finlandais, grec, norvégien, russe.
# Traitement avec ELO
Veuillez consulter ce schéma simplifié pour comprendre le traitement effectué par ELO.

Le serveur d'indexation ELO transfère les données à Elasticsearch, qui effectue sa propre analyse linguistique lors de l'indexation et la recherche. Les données d'indexation sont enregistrées dans des index Lucene.
Pour la recherche dans l'index, il faut un accès aux éléments suivants :
- fichiers d'index
- base de données Lucene
- outil d'analyse linguistique Elasticsearch
- serveur d'indexation ELO (ELOix)
# Sécurité
Depuis la version 10.2, la communication entre le Elasticseach et le serveur d'indexation ELO est cryptée. Pour ceci, le plugiciel Search Guard est utilisé.
# Installation et migration
# ELO Server Setup
L'installation ou une mise à jour du client Web se fait par le biais de l'installation serveur. Serversetup crée la configuration, installe le programme Elasticsearch et le service, ainsi qu'un répertoire de données dans lequel sont enregistrés les données d'indexation. Les options suivantes peuvent être sélectionnées dans ELO Server Setup :
- Nom du service
- Valeur mémoire
- Port
- Répertoire de données

- Avec ELOenterprise, d'autres serveurs Elasticsearch (pour ceci, voir le chapitre Licences pour la répartition des processus serveur).
Remarque
A partir de ELO 21.2, le port de ELO iSearch (standard : 9200) est sécurisé avec TLS/SSL.
Lors de l'appel via un navigateur, un avertissement de certificat est affiché lors du premier accès le cas échéant.
Selon le navigateur et le système d'exploitation utilisé, vous devez copier le certificat proposé dans la mémoire de certificats du navigateur, ou dans la mémoire de certificats du système d'exploitation. Par exemple, lors de l'utilisation de Microsoft Edge ou de Google Chrome, vous pouvez charger le fichierkeystore.jks depuis <ELO>\config\elastic\<Server ELO iSearch>\certificates dans la mémoire de certificats Windows, sous Windows. Si vous utilisez Mozilla Firefox, copiez le certificat dans la mémoire de certificats de Firefox en confirmant le message d'avertissement.
# Vérifications après l'installation
Après l'installation, vous permet appeler (en tant qu'administrateur Tomcat) https://<serveur>.<port> (le port standard est 9200). Si vous utilisez un navigateur quelconque, un fichier JSON est créé. Vous pouvez l'ouvrir dans un éditeur.
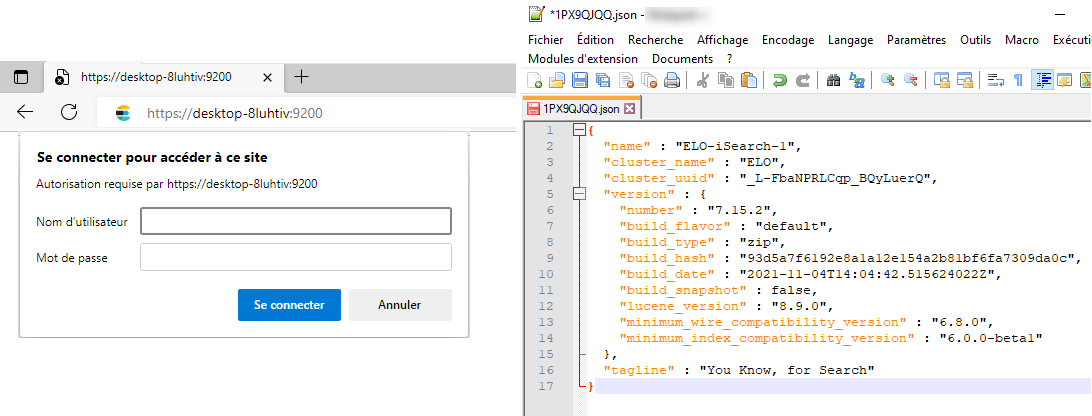
Cela permet d'afficher des données de base importantes, comme la version et le nom.
La cofiguration de ELO iSearch permet d'effectuer d'autres vérifications. Pour atteindre la configuration, vous pouvez passer par le biais de la page de configuration du serveur d'indexation ou par le lien suivant (authentification en tant qu'administrateur Tomcat) :
https://<server>:<ixport>/ix-<REPOSITORY>/manager/esconfig/#/iSearchConfig
# Création de l'index après la mise à jour d'anciennes versions ELO
Une réindexation des données d'indexation vers la version 23 LTS est nécessaire après une mise à jour d'une version ELO précédente (jusqu'à 21.01 incluse). ELO Server Setup supprime les indexes de Elasticsearch, étant donné que ceux-ci ne sont plus compatibles avec la version actuelle de Elasticsearch.
Lors de la réindexation, l'index est supprimé, puis reconstruit. Tous les champs sont enregistrés aussi bien avec le principe de tokenization que sans celui-ci, de manière à ce qu'une modification de ce réglage ne requiert pas de réindexation. De plus, les fichiers plein texte FT*.txt (créés par le processus de plein texte ELO) sont lus et utilisés pour l'indexation.
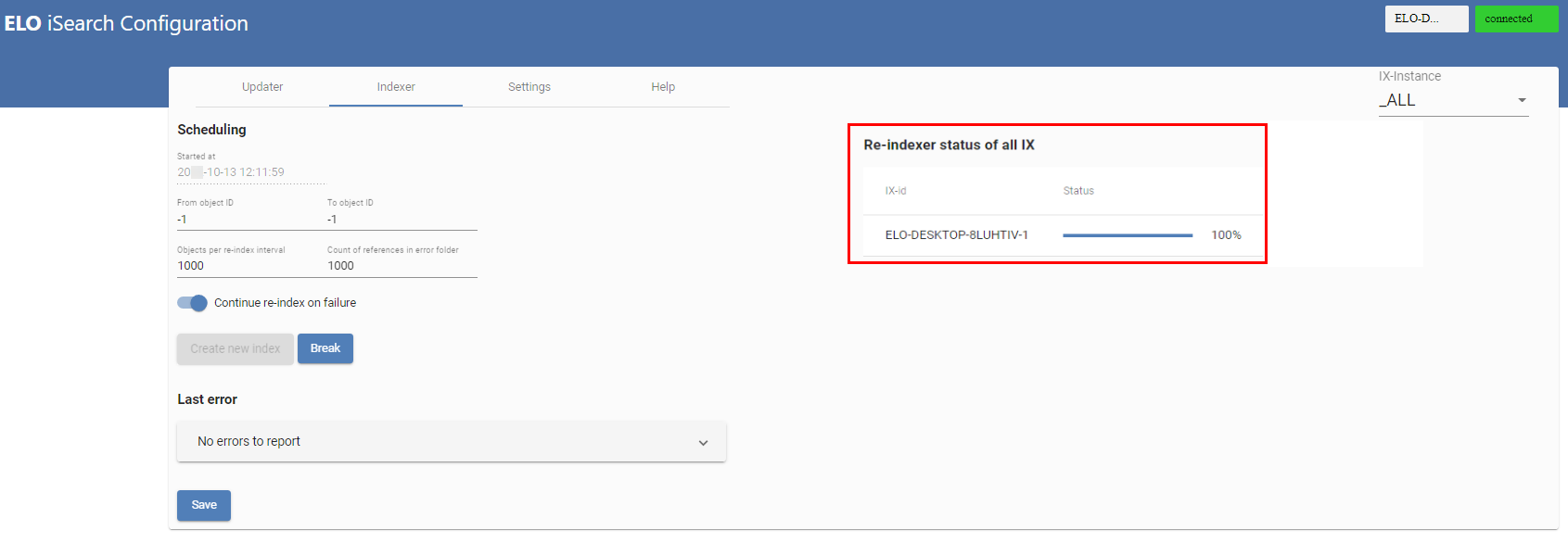
Une réindexation est effectuée par le biais de la configuration ELO iSearch dans l'onglet Indexer.
La progression s'affiche après l'actualisation de la page :
# Structure de l'index à l'arrière-plan
Lors de mises à jour à partir de la version ELO 9.3., il est possible par le biais de ELO Server Setup d'installer un serveur d'indexation ELO isolé avec la fonction Upgrade Index qui reconstruit l'index Elasticsearch. C'est notamment sensé dans les grands systèmes, pour lesquels la ré-indexation dure plusieurs jours. Vous pouvez utiliser cette fonction aussi bien pour une mise à jour vers une version plus actuelle d'ELO que pour des modifications dans les réglages de iSearch.

Vous pouvez utiliser cet index lors d'une mise à niveau ELO, de manière à pouvoir utiliser toutes les fonctions de recherche directement après la mise à niveau.
Vous trouverez plus de détails à ce sujet dans la documentation Création de l'index à l'arrière-plan.
# Sizing et performance
Une recherche performante est importante pour l'acceptation du système ELO. C'est pourquoi il est très important d'effectuer une optimisation de Elasticsearch de temps en temps, en plus de l'optimisation de la performance de la base de données (par exemple, deux fois par an, selon le nombre de documents et de données). Cette nécessité devrait être vérifiée du côté utilisateur (grâce à l'exécution de recherches complexes), et du côté serveur (par des analyses de fichier journal occasionnelles, voir le chapitre dédié à Fichier log).
# Informations sur le "sizing"
La performance de Elasticsearch est influencée par les facteurs suivants :
- Mémoire de travail, aussi bien pour JVM (Java Virtual Machine) de Elasticsearch, de la mémoire supplémentaire de Elasticsearch pour les caches, mais aussi pour le système d'exploitation en général.
- Nombre de processus
- Technologie de stockage
Voici quelques informations sur le dimensionnement :
- Mémoire de travail (voir aussi le paragraphe Dimensionnement de la mémoire de travail) :
- Les 4 GB + 4 GB de mémoire de travail libre définis comme standards suffisent pour les petits environnements.
- Nous vous recommandons de prévoir environ 24 GB (12 GB + 12 GB) pour des environnements de taille moyenne (environ 10 millions de documents).
- Pour les grands environnements, il existe une limite de 30 GB par JVM, et une répartition sur plusieurs clusters est recommandée.
- Processeurs
- Un thread est requis par recherche, cela signifie q'un nombre plus élevés de processeurs permet une meilleure parallélisation.
- Disques durs :
- Nous vous recommandons de travailler avec des disques durs rapides et performants. Un storage sur la base SSD est recommandée pour l'exploitation de Elasticsearch.
Pour les environnements de moyenne taille, nous vous recommandons d'utiliser ELOenterprise (voir Conditions de licence lors de la répartition des processus serveur).
# Redimensionnement de la mémoire de travail
Pour ce qui est de Elasticsearch, l'utilisation de la mémoire ne dépend pas que du nombre et de la taille de documents, mais aussi du type d'utilisation de la part des utilisateurs.
Il faut faire une différenciation entre Java Heap pour le service de ELO iSearch et le RAM requis par ailleurs pour Elasticsearch. Nous vous recommandons de mettre à disposition au moins autant de mémoire libre que ce qui a été configuré pour Java-Heap.
Java Heap peut être configuré dans le service de ELO iSearch, par exemple 10 GB, et 4 GB pour une nouvelle installation ELO. La même mémoire libre devrait être disponible pour le système d'exploitation pour Elasticsearch en tant que cache du système de fichiers. Elasticsearch utilise cette mémoire parce qu'elle est utilisée par le système d'exploitation en tant que cache du système de fichiers. Pour ce qui est du contenu, l'on y trouve principalement des données d'indexation (fixes et temporaires) et certains types de cache pour les requêtes de recherche.
Dans Java Heap, vous trouverez l'application Elastic, entre autre un volume de base de mémoire par shard (index lucene), ainsi que le cache query et le cache fielddata.
Pour la taille initiale de Java Heaps, il est possible d'indiquer une valeur indicative qui devra être adaptée ultérieurement selon l'utilisation : 4 GB à la base plus une mémoire utilisée actuellement (1 GB pour 1 million de documents ELO serait un bon début). A part cela, il vaut mieux travailler avec le cache du système de fichiers. Sur la base de notre expérience, le bon réglage pour Java Heap pour environ 10 millions de documents devrait se trouver entre 8 et 16 GB. La valeur exacte dépend de l'utilisation et du type des champs d'indexation. Par exemple, lorsque les utilisateurs utilisent souvent des filtres pour les champs d'indexation dans le client ELO, qui sont marqués comme étant tokenized et que des termes de contexte (par exemple des valeurs de filtre qui peuvent être sélectionnées pour ce champ) et que l'index pour ce masque contient des millions de document, alors toutes les valeurs de champs potentiellement disponibles sont chargées dans Java Heap et se retrouvent dans le cache Fielddata. Cela permet de faire grandir considérablement la taille du cache et ainsi du Java Heap requis. Cela se fait aussi lors d'un tri sur ce type de champs. Au contraire, si l'agrégation se fait seulement sur les champs notTokenized ou qu'aucunes propositions de filtre ne sont exigées par l'utilisateur, cela n'influence pas le cache de fielddata; les contenus de champs se retrouvent dans des fichiers temporaires virtuels, qui pourront être retrouvés dans le cache du système de fichiers du système d'exploitation. Cela complique la définition du réglage de Java Heap.
Remarque
Un index Elasticsearch est créé pour chaque masque. Celui-ci requiert environ 50 MB Java Heap pour 1 système d'un noeud sans replica. Un nombre important de masques requiert un besoin important de Java Heap et ainsi, d'une bonne mémoire de travail pour ELO iSearch.
Lors de la configuration de masques, le nombre de masques utilisés ne devrait pas dépasser les deux chiffres. Cela vaut aussi bien pour les masques de la première et de la seconde génération.
Par exemple, il y a encore un serveur d'indexation ELO, ELO Textreader et ELO OCR, dont l'utilisation n'est pas définie uniquement par la mémoire configurée, mais qui requiert également beaucoup du cache du système de fichiers. Vous pouvez reconnaître le volume global pour chaque application dans une application de gestion des tâches de votre système d'exploitation. Ensuite, ajoutez la consommation du système d'exploitation. La mémoire RAM du système se compose de cette valeur déterminée, du Java Heap configuré pour Elasticsearch et au moins de la même mémoire libre pour le cache du système de fichiers Elastic.
Exemple :
ELOix/ELOtr/ELOocr/le système d'exploitation requièrent par exemple 12 GB. ELO iSearch est configuré à 8 GB et requiert en plus le cache du système de fichiers de 8 GB. L'affectation est 12 GB + 8 GB + 8 GB = 28 GB. Dans un système de 32 GB, il y aurait encore de la place pour 4 GB. Cela n'est pas vraiment beaucoup lorsque l'archive devient nettement plus conséquente.
Pour les systèmes plus importants, nous vous recommandons d'installer ELO iSearch sur une machine virtuelle distincte ou sur un ordinateur distinct, afin qu'il n'y ait pas de situations concurrentielles avec le cache du système de fichiers et pour éviter que le système d'exploitation soit obligée de procéder à des délocalisations.
Le mieux est de ne pas utiliser plus de Java Heap que nécessaire, mais autant de cache du système de fichier possible.
Information
Nous vous recommandons de sélectionner le Java Heap de ELO iSearch dans ELO Server Setup.
De plus, vous avez la possibilité de configurer Java-Heap dans le fichier <ELO>\config\elastic\ELO-<Instanzname>\jvm.options.d\ELO-<Instanzname>.options ans le répertoire ELO. Une fois la configuration modifiée, vous devez redémarrer ELO iSearch. Toutefois, les modifications seront perdues lors de la prochaine actualisation de ELO Server Setup, c'est pour cela que cette modification n'est appropriée qu'à des fins de test.
Vous trouverez des informations sur la surveillance Java de ELO iSearch à des fins d'analyse et d'assistance dans la documentation ELO Server > Maintenance et surveillance > Surveillance de l'environnement Java > Serveur > ELO iSearch (opens new window).
# Optimisation de l'indexation
L'indexation ne peut pas réellement être optimisée. Le nombre de documents pouvant être indexés en même temps est déterminé par le serveur d'indexation ELO (ELOix). Les valeurs empiriques pour la création de l'index se situent entre 2 et 3 millions de documents par jour, y compris les documents en texte intégral, dans un environnement bien équipé.
Si l'option Enregistrer dans le plein texte (opens new window) n'est pas activée pour un document ELO, aucun document en texte intégral n'est créé et n'est donc pas disponible pour l'indexation. La ré-indexation peut donc être accélérée s'il y a moins de documents en texte intégral. La taille du plein texte joue également un rôle pour la rapidité. L'option maxFulltextContentMB dans Indexserver Configure Options (opens new window) du serveur d'indexation ELO vous permet de définir la taille maximale du texte intégral d'un document utilisé pour l'indexation. Les documents contenant uniquement des métadonnées, sans texte intégral, sont réindexés beaucoup plus rapidement.
# Optimisation de la rapidité de la recherche
Les facteurs de la performance ont déjà été décrits dans le chapitre Informations générales au sujet du sizing. Dans des grands environnements, cela a également une influence positive sur la vitesse de recherche, étant donné que le nombre de shards par index augmente, si ceux-ci sont répartis sur plusieurs noeuds. Veuillez noter qu'un ajustement du nombre de shards requiert une réindexation. Pour obtenir des informations sur le nombre de shards, veuillez lire le chapitre Définition du nombre de shards par index.
# Besoin d'espace isque pour les indexs de Elasticsearch
L'espace disque requis pour les index Elasticsearch dépend de divers facteurs, dont l'importance varie d'une archive client à l'autre. Les facteurs principaux sont :
- le nombre de documents et de classeurs
- le nombre et les types des champs spécifiques aux clients et aux solutions dans les masques (champs d'indexation)
- pour chqaue champ le nombre de données qui sont contenues. Ici aussi, la cardinalité du champ joue un rôle. Pour les métadonnées de la génération 1, la polyvalence est définie par ce qu'on appelle l'index de colonne ; pour les métadonnées de la génération 2, c'est la propriété indiquant si l'affectation d'aspect correspondante a une cardinalité MANY (c'est-à-dire si la cardinalité est égale à MANDATORY_MANY ou OPTIONAL_MANY).
- le paramètre permettant de déterminer si le texte intégral doit être généré et indexé, la proportion de documents en texte intégral par rapport au nombre total de documents, ainsi que le paramètre limitant la taille du texte intégral à indexer (maxFulltextContentMB)
- À partir de la version 25.1 d'ELO, le paramètre permettant de déterminer si des vecteurs IA doivent être générés et indexés pour le texte intégral, ainsi que la taille du texte intégral
- pour les champs de métadonnées du type Relation, les champs supplémentaires du document référencé marqués (paramétrable) sont intégrés dans le document à référencer
- pour les documents situés dans une région (par exemple, les documents rattachés à un objet business), d'autres champs de l'objet de région, marqués (paramétrables), sont également inclus dans les documents situés dans cette région
Étant donné que ces facteurs varient considérablement d'une archive client à l'autre, il n'est pas possible de fournir une estimation suffisamment précise de l'espace disque nécessaire.
# Espace requis pour les documents supprimés
Les documents marqués comme supprimés dans ELO sont des documents à part entière dans ELO iSearch. Ils doivent pouvoir être recherchés et trouvés via l'API lorsque la recherche est effectuée dans le client avec l'option documents supprimés inclus ou documents supprimés uniquement. C'est pourquoi les documents marqués comme supprimés continuent d'occuper de l'espace dans les caches Elasticsearch de Java Heap et dans le cache du système de fichiers (RAM). En termes d'espace disque occupé, il s'agit également de documents à part entière.
En revanche, les documents définitivement supprimés ne peuvent être ni recherchés ni trouvés. Ils n'occupent plus d'espace dans Java Heap ou le cache du système de fichiers (RAM). Ils continuent toutefois d'occuper de l'espace disque dans l'index, car ils sont marqués comme supprimés selon les règles internes d'Elasticsearch ou de Lucene et peuvent être progressivement supprimés ultérieurement lors des opérations de fusion de segments. En revanche, lors d'une réindexation, tous les index sont supprimés, et donc également tous les documents dans ELO iSearch.
# Exploitation
Il existe deux parties importantes pour l'exploitation de Elasticsearch :
- Fichiers log et leur contenu
- Création d'analyses
# Fichier journal
De façon standard, les fichier journaux de Elasticsearch se trouvent dans le répertoire d'installation ELO sous le répertoire logs.
Le fichier log ELO.log est le fichier en question, et ELO-<date>.log pour les fichiers journaux plus anciens.
Dans certains cas, il pourrait être sensé de jeter un coup d'oeil au fichier journal du serveur d'indexation (ix-<Repository>.log). Par exemple, pour ELO 11 et ELO 12, vous pouvez rechercher le terme queryTerm dans le fichier journal. Voici un exemple d'output pour une recherche du terme test dans le plein texte :
22:51:34,723 eloix-find-40 eloix-find-40 INFO (ElasticClient.java:183) - find(searchId=[(09A4500F-6BC6-4ECF-EFD6-A9E6B78C5A91)], queryTerm=Test, sort=IDATE\_DESC, highlightedText=false, resultField=true, relevance=true, currentFolderId=0, searchIn=2)
# Analyses
Vous pouvez demander le statut de Elasticsearch par le biais d'un navigateur. Vous pouvez également utiliser ces informations pour des solutions de monitoring (par exemple Nagios) Un compte Tomcat administratif est requis pour l'authenfication. Un fichier JSON est créé; celui-ci peut être affiché directement avec le navigateur Mozilla Firefox, comme dans la capture d'image suivante.
L'adresse URL pour Health est : https://<server>:9200/_cluster/health?pretty=true.
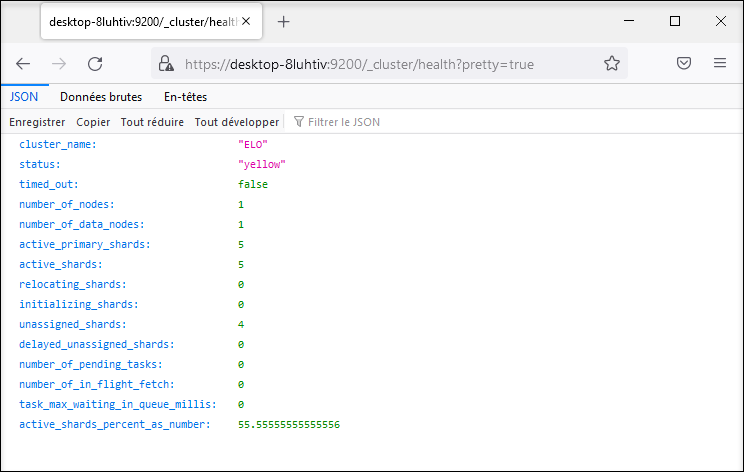
Le statut yellow signifie que l'index fonctionne, mais que les shards Replica ne sont pas tous disponibles. Le statut yellow est normal dans un environnement de serveur unique dans lequel le réglage standard est utilisé pour les Replicas (1).
L'URL pour le nom de répertoire de l'index est : https://<server>:<port>/_cat/indices.
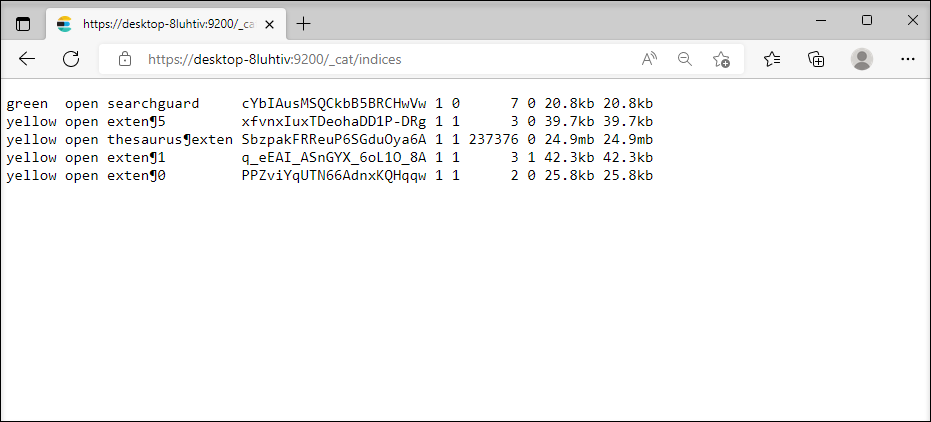
Il existe un index pour chaque masque; peut être reconnu à l'ID correspondant.
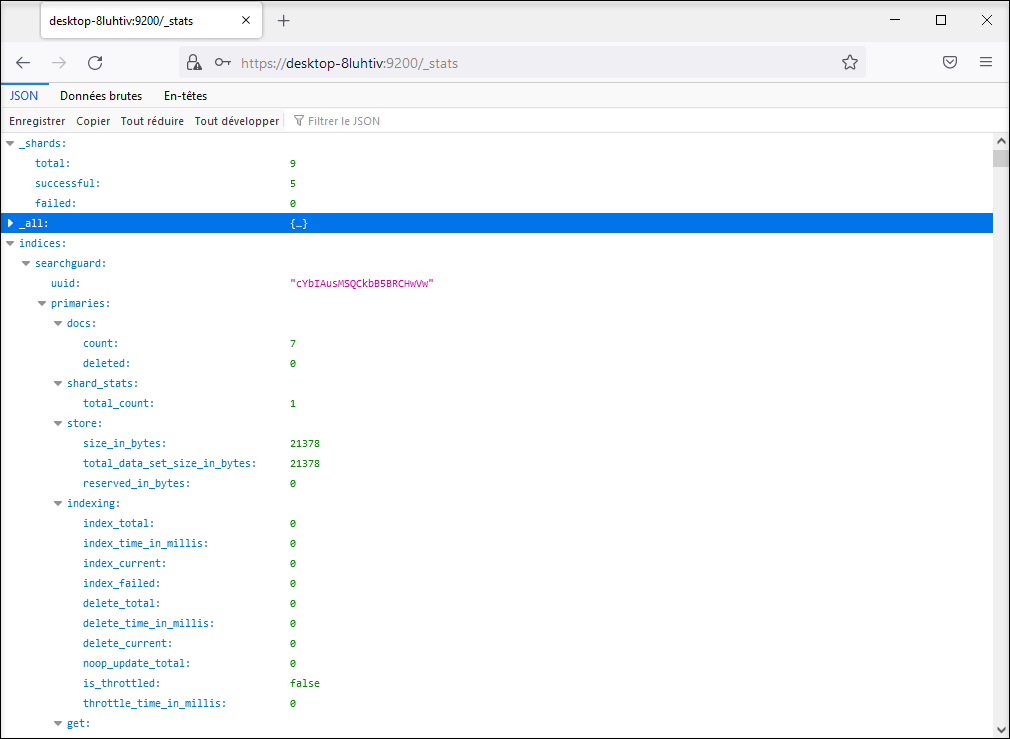
L'adresse URL pour les statistiques est : https://\<server\>:9200/_stats.
Vous pouvez vérifier si un nouveau document a été enregistré dans l'index. Lorsqu'un nouveau document a été enregistré, la requête de count dans la première ligne a pour résultat une valeur 1.
D'autres requêtes sont possibles sous la même forme. Celles-ci sont décrites dans la documentation en ligne de Elasticsearch.
# Possibilités et stratégies de sauvegarde
Les données de iSearch peuvent être restaurées à 100% depuis la base de données et le serveur d'indexation. Les facteurs suivants entrent en compte pour décider si une sauvegarde de l'index Elasticsearch doit être effectuée.
- Quel "downtime" de iSearch est recommandé pour les utilisateurs ?
Si le "downtime" doit être le plus bas possible, il est nécessaire d'avoir stratégie de sauvegarde avec laquelle l'index iSearch sécurisé auparavant peut être enregistré rapidement dans le système productif.
- Comment de temps cela dure-t-il de restaurer l'index iSearch ?
La durée de la ré-indexation initiale peut être une indication pour les prochaines ré-indexation. Vous devez décider si cette durée est acceptable pour les utilisateurs.
Vous avez deux possibilités pour créer une sauvegarde : Les index entre différentes versions de ELOix ne doivent pas forcément être compatibles. Une fois la sauvegarde enregistrée, il est nécessaire de ré-indexer les documents qui ont changé depuis la création de la sauvegarde. Cela peut être réalisé par le biais du processus Updater de la iSearch.
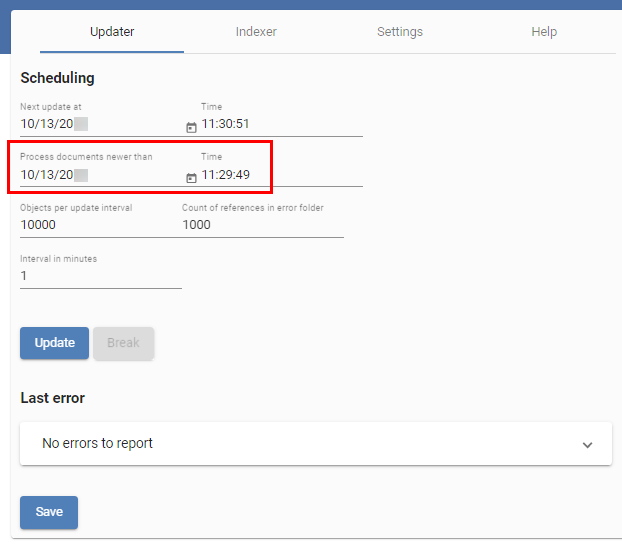
Le moment pour Process documents newer than est le même que lorsque la sauvegarde a été créée. C'est pourquoi il est sensé d'effectuer une sauvegarde tous les jours ou au moins une fois par semaine, afin que la durée d'indexation des documents modifiés ne soit pas trop longue.
Par ailleurs, veuillez noter que l'index nommé searchguard est requis, afin d'assurer le cryptage SSL par le biais de Search Guard Plugin. Si cet index n'existe pas, le serveur d'indexation ne peut pas se connecter à Elasticsearch. Si vous avez par mégarde supprimé l'index searchguard, vous pouvez le créer en exécutant Server Setup. Par ailleurs, le searchguard-Index dépend de l'administrateur Tomcat, de façon à ce que l'index ne puisse pas être copié s'il existe différents comptes ou mots de passe. Au contraire, il doit être créé par le biais de Server Setup.
# Copier l'index existant
Vous pouvez copier l'index existant dans le système de fichiers, puis l'utiliser ultérieurement. Pour ceci, vous devez copier l'intégralité du classeur sous <répertoire d'installation>/data/<…><nom du serveur>/index en tant que sauvegarde. Lorsque la sauvegarde est requise, vous pouvez remplacer le contenu du classeur nommé ci-dessus par la sauvegarde.
Le service iSearch doit être arrêté avec la copie, pour éviter des erreurs d'accès.
# Faire un snapshot avec Elasticsearch
Elasticsearch permet de créer des snapshots des index existants. Si vous créez des snapshots régulièrement, le logiciel ne crée pas une copie intégrale à chaque fois. Seuls les fichiers modifiés sont enregistrés, ce qui permet de réduire la mémoire requise.
Vous trouverez de plus amples explications sous :
Remarque
Pour restaurer un snapshot, le fichier de configuration de Elasticsearch (<répertoire d'installation>/config/elastic/<nom du serveur>/elasticsearch.yml) doit être complété par la ligne suivante: searchguard.enable_snapshot_restore_privilege: true
# Astuces
# Configuration de ELO l'iSearch
Vous pouvez appeler la configuration d'ELO iSearch via la page de configuration du serveur d'indexation (celle-ci est disponible à partir de ELO 11) :
https://<server>:<Port>:/ix-<Repository>/manager/esconfig/#/isearchConfig
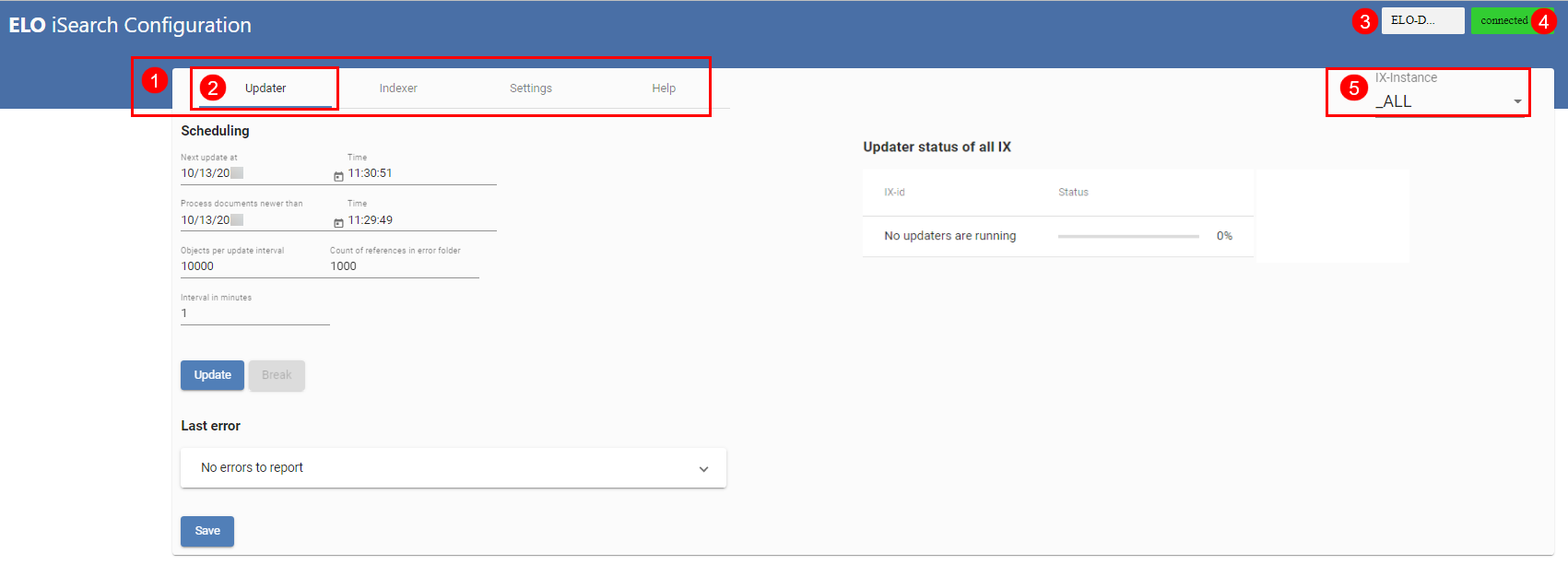
Dans l'illustration ci-dessus, vous voyez la configuration de ELO iSearch Vous pouvez appeler les différentes fonctions de iSearch par le biais de la configuration de ELO iSearch (1), l'onglet actif est marqué d'un trait bleu (2). En haut à droite (3), vous voyez le nom de l'instance ELOix qui a été appelée par le biais de la configuration de ELO iSearch, le statut de connexion à iSearch (4) est connected ou disconnected.
A partir de ELO 11, les réglages pour iSearch sont enregistrés dans le tableau eloixopt, puis ils sont enregistrés pour les différentes instances ou pour toutes les instances (_ALL), tout comme les options du serveur d'indexation. Dans le tableau, tous les réglages iSearch sont dotés du préfixe esearch. La configuration de ELO iSearch vous permet de faire afficher et modifier les réglages pour toutes les instances (ALL) ou de manière spécifique pour chaque instance (5).
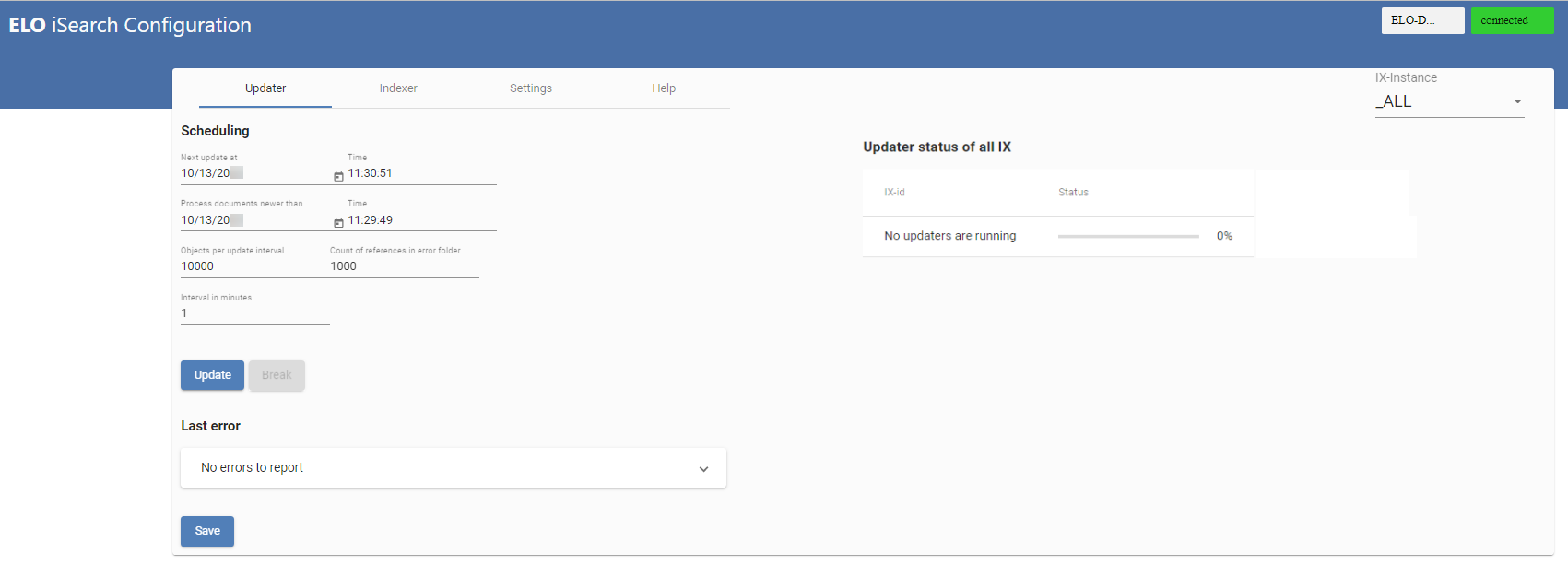
# Updater
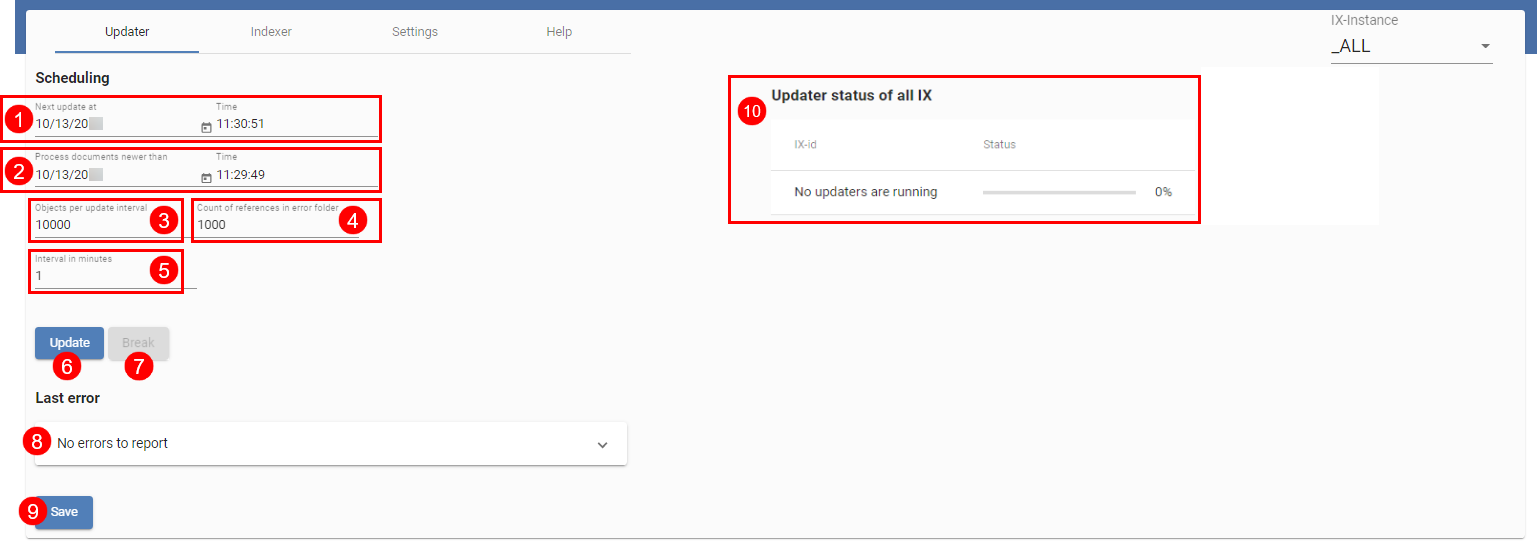
Dans l'illustration ci-dessus, vous voyez aperçu du Updater. Le Updater est requis pour l'actualisation régulière de iSearch. Par ailleurs, il fait en sorte que les nouveaux objets ainsi que les objets modifiés soient envoyés à iSearch. Dans la ligne supérieure (1), vous pouvez voir le prochain démarrage du Updater et dans la prochaine ligne (2), vous pouvez voir à partir de quand les documents doivent être traités. Vous pouvez ajuster les deux valeurs. Dans la configuration standard, le Updater est actif toutes les minutes (5) et traite au plus 1000 objets (3) dans la plus petite unité de temps (1 minute). Le nombre d'objets sélectionné reste dans la mémoire de ELOix, la valeur devrait être effectuée avec prudence.
S'il existe des problèmes lors de l'indexation d'un document, une référence vers le document dans l'archive ELO est créée sous le chemin suivant :
Administration // Fulltext Configuration // Update Errors
De cette manière, vous pouvez contrôler si des erreurs sont apparues. Par ailleurs, il peut faire en sorte que les documents soient à nouveau envoyés à iSearch, par exemple en ouvrant le dialogue Métadonnées. Le nom nombre max. de documents dans ce classeur est défini sous (4). Le réglage 0 fait qu'aucune référence n'est créée.
Si vous effectuez des modifications, vous devez les enregistrer avec Save (9).
Un aperçu de tous les processus en cours se trouve dans la section Updater status of all IX (10). Un processus de mise à jour peut être démarré manuellement par le biais du bouton Update (6) ainsi que par le biais du bouton Break (7). Les fonctions Démarrer et Annuler se réfèrent toujours à l'instance ELOix actuelle.
La dernière erreur du processus de mise à jour s'affiche dans Last Error (8).
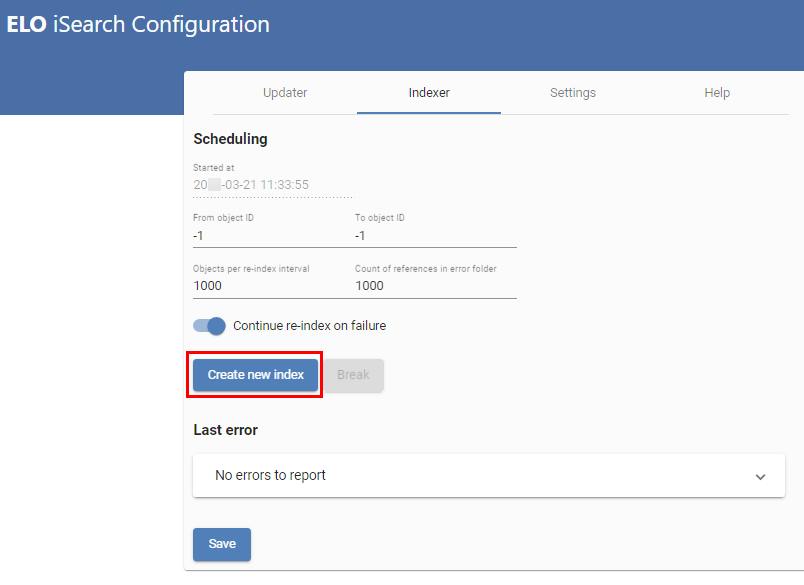
# Indexer
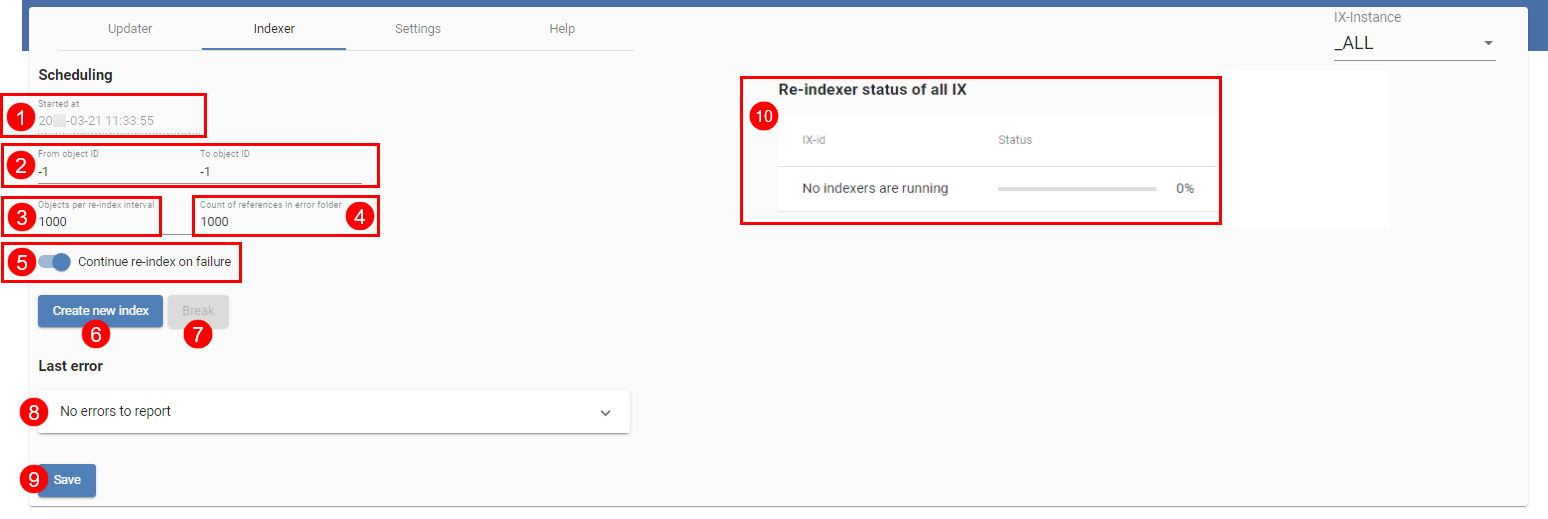
Le Indexer (illustration ci-dessus) vous permet de prendre le remplissage initial de iSearch avec les objets de l'archive ELO. Pour ceci, tous les objets existants sont envoyés à iSearch. Le début se fait avec les objets de l'ID le plus élevé, l'indexation se fait par ordre décroissant. Ainsi, les nouveaux objets sont trouvés plus tôt, si l'index est tout de suite utilisé dans un environnement productif.
Dans la ligne supérieure (1), vous voyez le point de démarrage du dernier processus de ré-indexation (2) et (3) vous permettent de sélectionner les ID d'objet qui sont indexés. Si vous souhaitez effectuer une ré-indexation complète, les deux valeurs doivent être placées sur -1. Cela entraîne aussi la suppression de l'index existant. Toutefois, si vous souhaitez ajouter seulement des objets précis à un index existant, vous pouvez le faire par le biais des IDs.
Les réglages pour les objets par intervalle d'indexation (3) et références dans l'archive (4) correspondent à celui de l'Updater. Les références sont déposées dans le classeur sous le chemin suivant :
Administration // Fulltext Configuration // Re-Index Errors
Cette valeur est la même, aussi bien pour l'Updater que pour l'Indexer.
Le réglage Continue Reindex on Failure (5) indique si le processus de réindexation doit être annulé ou poursuivi en cas d'erreur. Si vous souhaitez qu'il poursuive, un contrôle régulier des fichiers journaux est absolument nécessaire.
La dernière erreur du processus de ré-indexation s'affiche dans Last Error (8).
Vous devez enregistrer tous les réglages par le biais du bouton Save (9).
Une ré-indexation peut être démarrée (lorsque les deux ID d'objet sont placés sur 1) poursuivie (6) et annulée (7). Comme pour l'Updater, vous devez prendre en compte que cette indication se réfère toujours à l'instance ELOix via laquelle la page de configuration a été appelée.
Un aperçu des processus de réindexation actifs se trouve dans (10).
# Settings
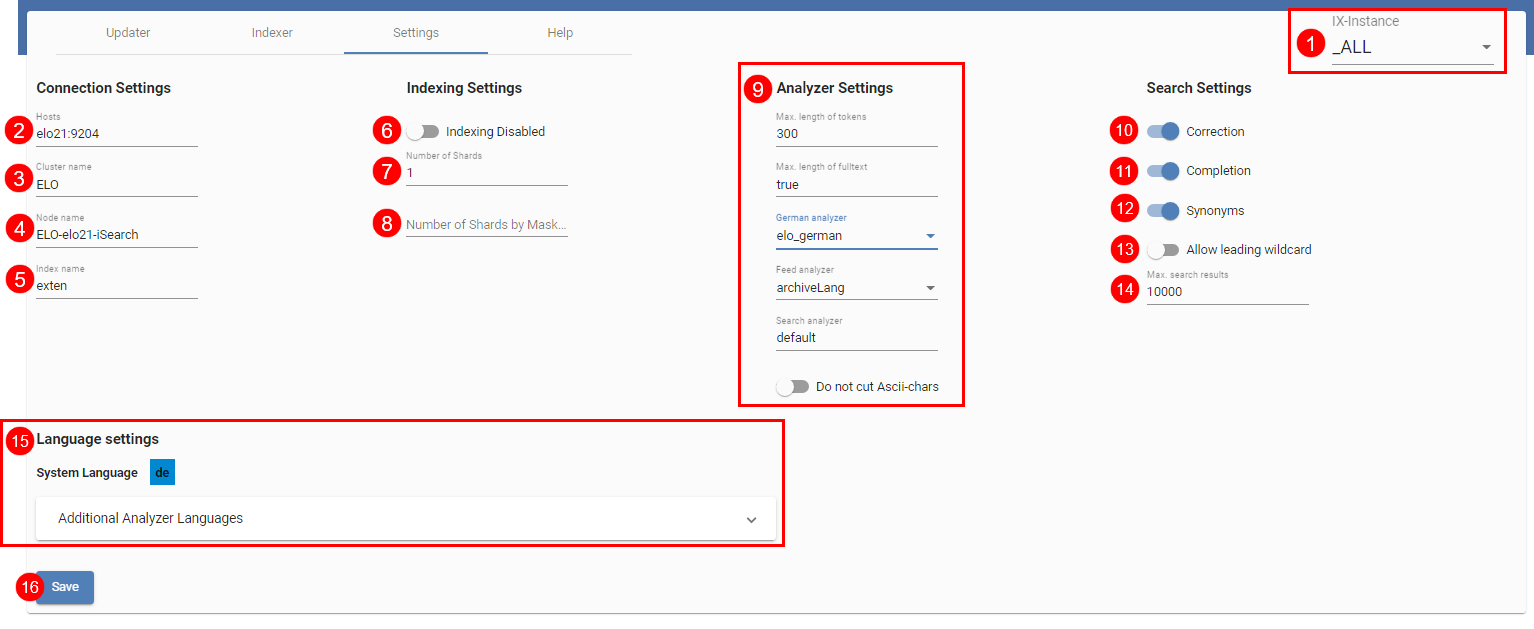
Un aperçu des autres possibilités de réglages de iSearch est illustré ci-dessus. Sous IX-Instance (1), vous pouvez sélectionner si les réglages doivent être effectués pour toutes les instances ou de manière plus spécifique (voir aussi l'illustration Configuration ELO iSearch, onglet 'Réglage', effectuer les réglages en fonction des instances).
Les détails de la création de connexion entre ELOix et Elasticsearch sont effectués sous (2), (3) et (4). Dans le standard, le nom de l'index Elasticsearch (5) correspond au nom de l'archive en minuscules.
Par ailleurs, vous pouvez indiquer si un ELOix doit être utilisé pour l'envoi d'objets à iSearch. Si ce réglage est actif, la recherche plein texte est tout de même active par le biais de iSearch.
Le nombre de shards ou le nombre de shards par masque est (7) et (8). Veuillez consulter le chapitre Définition du nombre de shards pour tout complément d'information.
Les réglages Analyzer (9) se réfèrent au traitement de texte envoyé à Elasticsearch. Si tout est normal, vous pouvez utiliser les pré-réglages existants.
Les réglages (10) à (14) se réfèrent à la recherche. Vous pouvez définir si la recherche doit également livrer des propositions de correction (10) ou des synonymes (12) suite à une recherche et si l'auto-remplissage (11) doit être actif lors de l'entrée de la recherche. Par ailleurs, vous pouvez activer la recherche avec un signe joker au début du terme de recherche (13). Ce signe est désactivé de manière standard, étant donné qu'une recherche avec le caractère joker peut ralentir Elasticsearch. Par ailleurs, vous pouvez définir le nombre de résultats max. (14), qui doivent apparaître par le biais des appels API ELOix findFirstSords() et findNextSords().
Vous pouvez modifier les réglages de langue de l'iSearch avec Language Settings (15). La langue système ou la langue d'archive est définie par le biais de Server Setup, elle ne peut pas être modifiée. En fonction des licences disponibles, vous pouvez sélectionner d'autres langues. Vous pouvez modifier les réglages de langue de l'iSearch avec Language Settings (15). La langue système ou la langue d'archive est définie par le biais de ELO Server Setup, elle ne peut pas être modifiée. En fonction des licences disponibles, vous pouvez sélectionner d'autres langues. Ces paramètres de langue déterminent, lors de l'indexation, si des étapes d'analyse spécifiques à la langue doivent être utilisées ou non pour un document dont la langue a été identifiée, lors de la génération des tokens. Par exemple, pour la langue allemand, un filtre Decompounder peut être utilisé pour décomposer des termes composés. Comme cela, il est possible de trouver également des mots partiels non composés. Dans ce cas, pour la langue anglaise, par exemple, les mots vides typiques peuvent être supprimés. Si, lors de l'indexation d'un document, une langue n'appartenant pas à la liste des langues configurées est détectée, le document est tout de même indexé, mais uniquement à l'aide des étapes d'analyse qui ne sont pas spécifiques à une langue (analyseurs de secours).
Vous devez enregistrer tous les réglages par le biais du bouton Save (16). Remarque : les réglages (5), (7), (8), (9) et (15) requièrent une ré-indexation, afin qu'ils valent pour toutes les données et que cela n'entraîne pas différentes données dans iSearch.
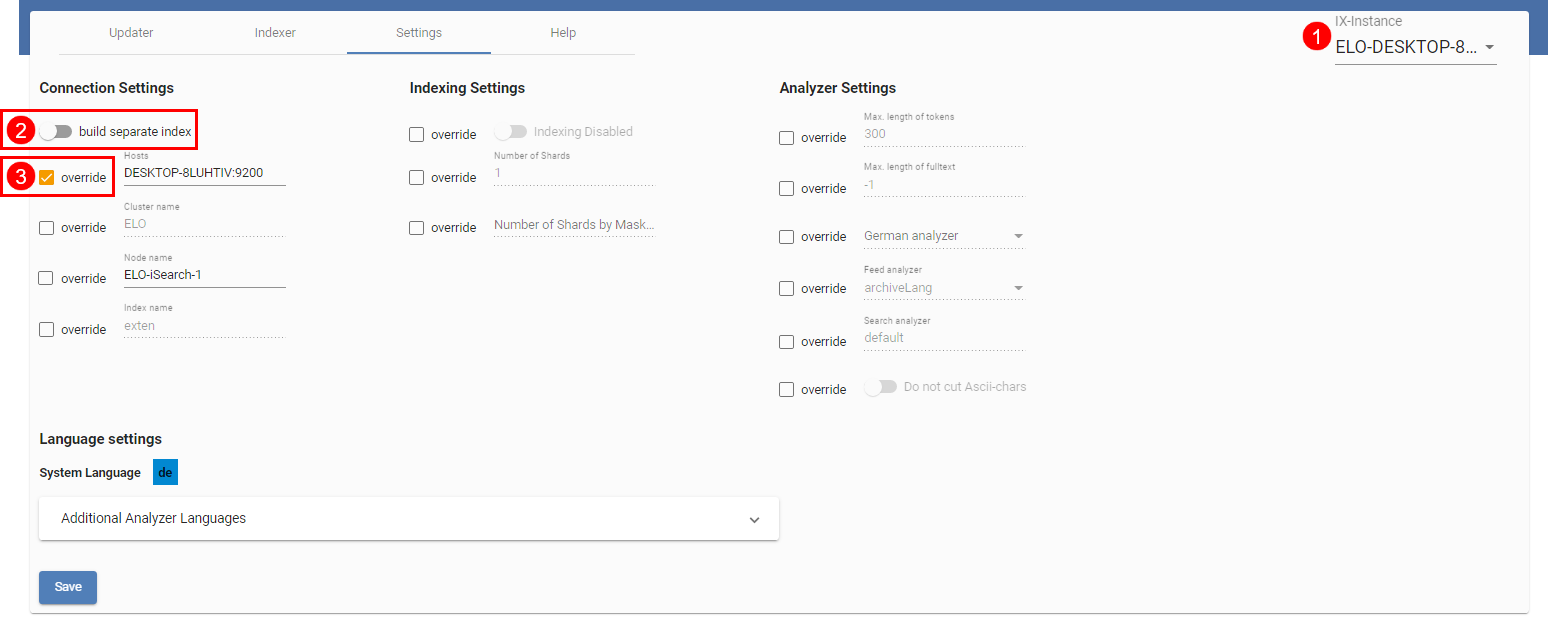
L'illustration montre la page de réglages pour l'instance ELO-DESKTOP-8LUHTIV (1). Tous les réglages pour lesquels la case à cocher Override est active (3), écrasent le réglage effectué pour toutes les instances.
Le réglage build separate index (2) ne concerne que différentes instances. Si ce réglage est actif, un index distinct est créé avec ce serveur d'indexation – mais seulement si les réglages de connexion diffèrent de ceux pour les autres instances ou si le nom d'indexation est différent. Vous trouverez des plus amples informations à ce sujet sous Création de l'index à l'arrière-plan.
# Configuration des services de Elasticsearch
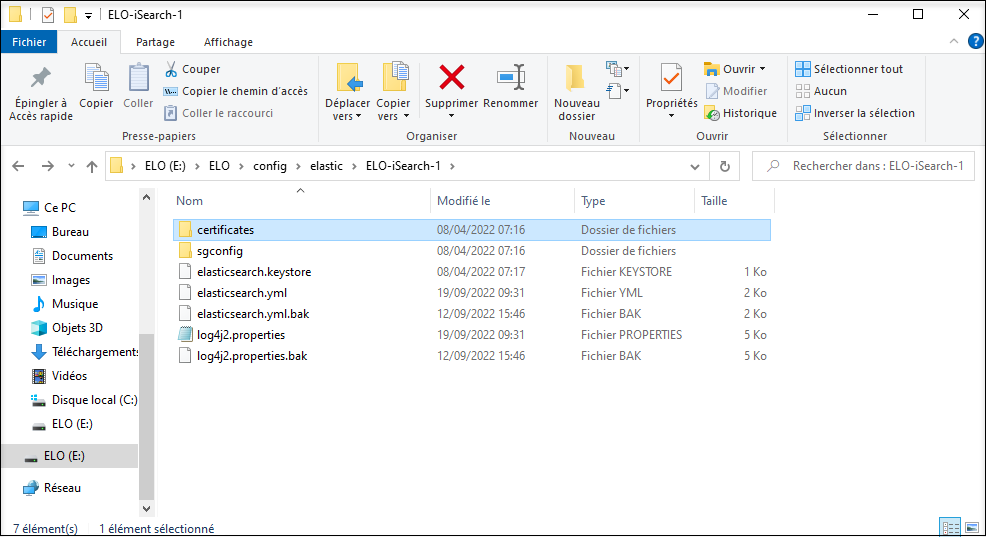
La configuration du service Elasticsearch se fait par le biais de plusieurs fichiers et répertoires.
Les fichiers et répertoires ont les contenus suivants :
elasticsearch.yml: fichier de configuration central de Elasticsearch. Vous trouverez des informations détaillées sous : https://www.elastic.co/guide/en/elasticsearch/reference/current/important-settings.html (opens new window)
Remarque
N'ajoutez pas d'options au fichier de configuration elasticsearch.yml, sauf si le support ELO vous le demande.
log4j.properties : réglages concernant la journalisation
sgconfig : répertoire avec les configurations des Search Guard Plugins
certificates : Keystore et Truststore pour la communication SSL avec le serveur d'indexation ELO
# Communication SSL
Depuis la version 10.2 de ELO ECM Suite, la communication entre Elasticseach et les serveurs d'indexation ELO est cryptée. Pour ceci, ELO Server Setup crée des certificats autosignés et des Keystores et Truststores correspondants lors de l'installation. Les Keystores et Truststores sont créés sous les répertoires config correspondants (serveur d'indexation et Elasticsearch et peuvent être ouverts avec les moyens Java standards (par exemple, keytool.exe) pour la vérification des certificats. Utilisez le mot de passe du compte administratif de Tomcat.
# Plugiciels du serveur d'indexation
A partir de ELO 11, il est possible d'élargir le serveur d'indexation par des plugiciels OSGi. Par exemple, l'interface Elasticsearch se trouve elle-même dans un tel plugiciel. Cette structure nous permet d'accéder à un nouvel index d'Elasticsearch avec une version moins récente du serveur d'indexation ELO. Un répertoire de plugiciel est configuré pour chaque serveur d'indexation.
# Définition du nombre de shards par index
A partir de ELO 11, un index est créé par masque. Dans le réglage standard, chaque index se compose d'un shard. La répartition en un index par masque permet d'améliorer la performance dans le cluster, étant donné que les index sont répartis sur plusieurs noeuds.
Par ailleurs, il est sensé de répartir les index particulièrement grands en plusieurs shards. L'avantage est que les recherches peuvent être effectuées parallèlement sur tous les shards. Attention : le nombre de requêtes effectuées parallèlement dans un noeud correspondant au nombre de processeurs.
Le nombre de shards se réfère aux données contenues. Elasticsearch recommande une taille de shard de 20 à 40 GB. Lorsque les shards sont trop petits, cela peut entraîner un surdébit de communication entre les shards, étant donné que les données entre les shards doivent être synchronisées. Les masques qui contiennent beaucoup de SORDs avec plein texte devraient être répartis dans plusieurs shards si possible.
Le nombre de shards par masque peut être effectué par la page de configuration de ELO iSearch, mais il requiert une réindexation de toutes les données.
# Définition du nombre de Replica par index
En quelque sorte, les réplicas sont les copies d'un index. Vous pouvez sélectionner une valeur quelconque, même 0. Pour chaque shard, est créé un shard primaire ainsi que le nombre indiqué de shards réplicas dans le cluster. Les shards primaires et les shards réplicas sont toujours créés sur différents noeuds, afin de pouvoir mettre à disposition les données en cas d'une défaillance. Lorsqu'un noeud est en défaillance, les shards primaires qui étaient jusqu'alors localisés sur ce noeud, sont localisés sur un autre noeud. Les shards réplicas sont répartis sur d'autres noeuds, pour assurer une fiabilité et une performance sans failles.
Un autre avantage considérable des réplica shards est de pouvoir traiter les recherches en parallèle : Elasticsearch répartit les requêtes sur différents shards primaires et réplica shards pour répartir la charge.
Le statut d'un index dépend de la disponibilité des shards. Si le shard primaire est disponible, le statut est jaune. Si tous les replica shards sont également disponible, le statut est vert.
Le nombre de réplica shards devrait être adapté au nombre de noeuds dans le cluster, de manière à ce que les shards puissent se répartir sur plusieurs noeuds et garantir qu'il n'y ait pas de problème de défaillance. D'un autre côté, chaque réplica requiert autant de mémoire que les primary shards.
Le réglage standard pour le nombre de réplicas est 1. Dans chaque cluster qui a plus d'une instance, chaque shard est répliqué une fois, il existe donc deux fois. Une modification du nombre de réplicas n'entraîne pas de ré-indexation.
Pour qu'une ré-indexation dans un cluster soit plus rapide, le nombre de réplicas peut obtenir la valeur 0 pendant la durée de la ré-indexation. Cette valeur peut être augmentée après la ré-indexation. Si le nombre de réplicas est supérieur à 0, les données sont indexées en même temps aussi bien dans Primary Shard que dans chaque réplica Shard. Cela signifie que l'analyse et la transformation en données Elasticsearch se fait plusieurs fois en parallèle. Si le nombre de réplicas est défini comme 0, les données ne sont traitées que dans un noeud pendant la réindexation. Dès que le nombre de réplicas est augmenté, les primary shards déjà indexés sont copiés sur les autres noeuds, ce qui va beaucoup plus vite le cas échéant. Bien sûr, il n'y a pas de scénario en cas de défaillance pendant la ré-indexation.
Ce réglage se réfère à un index et peut être modifié avec l'outil curl (https://curl.haxx.se/ (opens new window)) pour le masque avec l'ID 42 de l'archive archive en 2 :
curl -X PUT "localhost:9200/repository¶42/_settings" -H 'Content-Type: application/json' -d'
{
"index" : {
"number_of_replicas" : 2
}
}
'
Si vous souhaitez modifier le réglage pour tous les index, vous pouvez utiliser l'URL localhost:9200/_settings.
# Tokenisation
L'option Désactiver la tokenisation d'un modèle de champ désactive les règles de recherche pour ce champ. Dans la liste apparaissent alors les valeurs exactes des métadonnées. La recherche travaille également dans un mode exact pour ce champ. Les parties de termes ne sont pas prises en compte dans ce cas.

En ce qui concerne les règles de recherche actives, seuls des termes uniques apparaissent dans la liste du filtre, aussi bien les originaux que les formes créées. Les possibilités de recherche dans ce filtre correspondent aux possibilités dans le champ d'entrée de la recherche.
# Intégration de propres thésaures
Vous pouvez adapter individuellement les dictionnaires pour le thésaure de ELO iSearch. Les fichiers requis se trouvent dans l'archive sous :
Administration // Fulltext Configuration // Thesaurus
Dans ce chemin, se trouve un sous-répertoire pour chaque langue, avec le raccourci du pays. Trois documents se trouvent dans chaque sous-répertoire.

<Langue>_thesaurus : le thésaure disponible proposé par ELO pour cette langue. Vous ne devriez pas modifier ce fichier, afin de pouvoir le remplacer par une nouvelle version lors d'une mise à jour.
<langue>_add : dans ce document, vous pouvez entrer des termes supplémentaires qui seront transmis au thésaure en tant que synonymes.
<langue>_stop : ce document vous permet d'exclure des termes du thésaure, si ceux-ci ne vous conviennent pas.
Remarque
Une fois les documents modifiés, le serveur d'indexation ELO doit être redémarré afin que le thésaure puisse être restructuré.
# Exploitation en mode cluster
Dans la documentation sur ELO iSearch, sous Serveur ELO - Installation et fonctionnement (opens new window), nous vous expliquons comment utiliser un cluster.
# Recommandations en cas de messages d'erreur
# Le message d'erreur contient le texte 'pending translog recovery'
Aprés un redémarrage non prévu du service ELO iSearch, des messages d'erreur peuvent survenir dans le fichier journal de iSearch, contenant le texte pending translog recovery.
Exemple :
[2023-06-29T13:22:51,662][WARN ][o.e.i.f.SyncedFlushService] [ELO-iSearch] failed to flush shard [contelo¶2][0], node[8NAibzRYQtqFpTY_Fl7mug], [P], recovery_source[existing store recovery; bootstrap_history_uuid=false], s[INITIALIZING], a[id=o1RcLpTjTdWLSNrMOnzlGA], unassigned_info[[reason=CLUSTER_RECOVERED], at[2023-06-29T11:05:49.208Z], delayed=false, allocation_status[deciders_throttled]] on inactive
java.lang.IllegalStateException: [contelo¶2][0] flushes are disabled - pending translog recovery
at org.elasticsearch.index.engine.InternalEngine.ensureCanFlush(InternalEngine.java:2572) ~[elasticsearch-7.15.2.jar:7.15.2]
Ces messages peuvent être très nombreux et apparaissent lorsque ELO iSearch a été arrêtée et n'a pas eu la possibilité de transférer toutes les transactions dans l'index (par exemple, lorsqu'il n'y a pas de mémoire principale).zahlrei Lors de l'activation, Elasticsearch essaiera de transférer le fichier translog dans l'index. S'il y a un volume important de données, cela peut durer une heure, ou même plusieurs heures. Pendant ce temps les indexes ne sont pas disponibles.
Recommandation :
Tout d'abord, nous vous recommandons d'attendre jusqu'à ce que le fichier log soit transféré dans l'index et que ces messages n'apparaissent plus. Ensuite, nous vous recommandons d'analyser quel problème d'origine a entraîné la fermeture du service ELO iSearch.
Evitez de démarrer une ré-indexation via la page de configuration de ELO iSearch, pendant l'apparition de ces messages. En règle générale, l'index est à nouveau consistant après la finalisation du translog recovery et une nouvelle ré-indexation n'est pas requise.
Si le système est arrêté de force pendant le translog recovery, les données de l'index pourraient être corrompues, et elles ne pourront pas être réparées via translog recovery. La conséquence est la nécessité d'une réindexation ou même de la nouvelle installation du service ELO iSearch.
# Arrêt de la ré-indexation en raison de trop d'articles du fil d'actualité
Si le processus de réindexation de iSearch ne fonctionne pas, dans certains cas très rares, il peut s'agir d'un nombre extrêmement haut d'articles du fil d'actualité. Cela peut être causé par des automatismes erronés, comme des processus d'importation ou des scripts qui déposent les documents et qui créent sans le vouloir un nombre énorme d'articles du fil d'actualité, le cas échéant avec des messages d'erreur.
Cela se voit à 2 endroits :
Le serveur d'indexation ELO annule avec le message d'erreur :
java.lang.OutOfMemoryError: Java heap space.Dans le fichier-journal du serveur d'indexation ELO, le tableau feedaction crée des exceptions SQL avec
read timed out. De plus, les entrées comportant un nombre élevé de contributions par document individuel sont affichées en premier.Exemple:
19:20:58.529 INFO esin-8 esin-8 (FeedIndexer.java:108) - [821022] indexFeed=true: posts=#145239
Pour voir si un nombre trop important d'articles du fil d'actualité sont l'origine pour l'interruption, vous pouvez effectuer une requête dans la base de données pour savoir pour quels SORDS (c'est-à-dire des documents ELO) existe un nombre important d'articles du fil d'actualité.
Exemple d'une requête SQL :
select count(*), objid
from documentfeed d
inner join feedaction f on d.feedguid=f.feedguid
inner join objekte o on d.objguid = o.objguid
group by objid
having count(f.feedguid) > 1000
order by 1 desc
Le nombre 1000 est un exemple pour un seuil pour beaucoup d'articles du fil d'actualité par document ELO. Si des valeurs très élevées (des dizaines de milliers ou des millions) apparaissent dans la première colonne de résultats, vous devez trouver la cause de ces entrées du fil d'actualité et corriger les automatismes défectueux.
Information
Dans le cas des petits systèmes ELO, un nombre total de plusieurs millions de contributions au flux peut également entraîner une charge accrue ou une consommation de mémoire plus importante du serveur d'indexation ELO. C'est le nombre global des entrées dans le tableau feedaction qui est pertinentr.
Après avoir corrigé les automatismes défectueux, remettez le système en état de fonctionnement comme suit.
Procédé
- Tout d'abord, vous devez sécuriser la base de données via une sauvegarde.
- Arrêtez toutes les instances ELOix pour la durée de la correction.
- Veuillez identifier feedguid pour le objguid correspondant dans le tableau documentfeed.
- Dans le tableau feedaction, supprimez les lignes avec feedguid qui ne sont plus requis ou ceux qui sont erronés.
- Option : dans le tableau feedactionhist (historique des modifications), veuillez identifier les actionguids correspondants pour le feedguid déterminé et supprimez dans le tableau feedactionhist les lignes correspondants à actionguids. Ils n'ont pas d'impact direct sur la réindexation, mais ils ne servent à rien si les entrées principales ont été supprimées.
- Au cas où toutes les lignes correspondantes ont été supprimées dans le tableau feedaction, (c'est à dire, au cas où tous ces posts du fil d'actualité sont erronés ou non intentionnées, vous devez supprimer (dans le tableau documentfeed la ligne avec cette feedguid (feedaction.feedguid = documentfeed.feedguid).
Alternative :
Si seulement les articles du fil d'actualité qui sont anciens ou qui ne sont plus requis doivent être purgés, il suffit d'exécuter les étapes de 1 à 6 sauf l'étape 3. Par exemple, toutes les entrées qui sont encore requises peuvent être copiées dans un tableau supplémentaire, puis renommées en feedaction.
# Power search
La power search de ELO iSearch vous permet d'effectuer des recherches complexes et d'utiliser la syntaxe de iSearch.
La power serach de ELO iSearch vous permet d'utiliser ElasticSearch. Vous avez deux nouvelles possibilités : d'une part, vous pouvez accéder directement aux champs qui ne sont pas disponibles par le biais d'un filtre. D'autres part, vous pouvez effectuer des demandes très complexes par le biais de la syntaxe proposée par Elasticsearch.
L'accès direct aux structures internes est en même temps l'inconvénient de power search, étant donné que la syntaxe est très technique et qu'il faut avoir des connaissances poussées en matière de structure de données interne. Par ailleurs, la structure interne peut changer dans les versions futures d'ELO, de façon à ce que les requêtes risquent de ne plus fonctionner.
Attention
Nous vous recommandons de n'utiliser la power search qu'exceptionnellement, par exemple, lorsque les possibilités de recherche courantes ne fonctionnent pas.
# Utilisation de power search
La power search peut être utilisée aussi bien dans le client Java ELO que dans le client Web ELO. La requête est entrée dans la ligne de recherche et est déclenchée par le biais de =, comme nous l'avons décrit dans l'exemple suivant.

Avec la power search, les requêtes sont envoyées directement à Elasticsearch par le biais du serveur d'indexation ELO. Le serveur d'indexation ELO effectue une vérification d'autorisations, de manière à ce que les utilisateurs ne peuvent visualiser que les documents pour lesquels ils détiennent le droit.
La syntaxe de la power search correspond à la syntaxe QueryStringQuery, comme elle est documentée par Elasticsearch sous ce lien :
Pour l'utilisation, il est important de savoir que vous devez échapper vous-même les caractères spéciaux. Cela peut être important dans le cas de figure suivant : lorsqu'un caractère spécial doit être interprété comme une lettre normale et non pas avec la signification qui pourrait influencer la recherche. Les caractères spéciaux ont une signification particulière dans la syntaxe QueryStringQuery et doivent être supprimés, si cette signification n'est pas voulue :
| Caractères | Signification |
|---|---|
| +<mot> | <mot> doit apparaître dans le document |
| -<mot> | <mot> ne doit pas survenir dans le document (sauf s'il y a un espace devant) |
| <mot1> && <mot2> | Les deux termes doivent apparaître dans le document |
| <terme1> et <terme2> séparés par deux symboles "Pipe" | Au moins un des deux termes doit apparaître dans le document. |
| > x < x | Plus grand / plus petit que …recherche (fonctionne avec des chiffres ou des mots) |
| >= x <= x | Plus grand ou égal / plus petit ou égal (fonctionne aussi bien avec des chiffres qu'avec des mots) |
| = | pas de signification tout seul, au début de la ligne : power search |
| {x TO y} | recherche de section (sans x et y) |
| [x TO y] | recherche de section (avec x et y) |
| <wort>^ | importance du mot |
| "<wort> <wort>" | recherche de fragments de phrase |
| <wort>~ | Fuzziness (recherche non précise) |
| * | Wildcard, nombre illimité de caractères |
| ? | Wildcard, nombre exact de caractères devant être remplacés |
| \ | caractères "Escaped" |
| / | pas de signification |
| <nom du champ>:<terme> | recherche dans <nom de champ> recherche du <terme> |
# Noms de champ
Les différents champs de Elasticsearch peuvent être parcourus directement, à condition que le nom du champ soit connu. Un aperçu des noms de champ n'est pas mis à disposition par ELO. L'administration peut toutefois effectuer une demande par le biais de l'interface REST de Elasticsearch :
http://<host>:<port>/<nom d'archive écrit en minuscule>/_mapping?pretty
Elasticsearch met à disposition d'autres informations sur l'interprétation de la demande sous le lien suivant : https://www.elastic.co/guide/en/elasticsearch/reference/5.6/index.html (opens new window)
Remarque
ELO se réserve le droit de modifier les champs de nom entre les versions. Ainsi, il se pourrait qu'une requête fonctionne avec une version, mais pas avec la version suivante.
# Exemples de requêtes
Souvent, il peut être sensé de regarder si un document précis peut être trouvé par le biais de iSearch. Cela peut se faire par le biais de la requête suivante :
=elo_id:<Objektid>
La condition préliminaire est que l'utilisateur qui cherche possède le droit Voir toutes les entrées, ignorer les autorisations. Si cela ne mène à aucun résultat, le document ne sera pas pris en compte par iSearch.
La recherche de ELO[123 mène à un erreur de syntaxe, étant donné que le crochet est un caractère particulier, qui peut également être utilisé pour la recherche de section. Pour tout de même recherche ce caractère, vous pouvez utiliser la power search en effectuant la requête suivante :
=ELO\[123
# Conditions de licence lors de la répartition des processus serveur
Les systèmes ELOprofessional ne sont que partiellement compatibles cluster, ils permettent uniquement l'exploitation hot standby des différents composants. En revanche, les systèmes ELOenterprise sont compatibles cluster.
En ce qui concerne ELOprofessional, les processus serveur ne peuvent être répartis que sur le même hôte, donc sur le même serveur. ELOenterprise, les processus peuvent être répartis sur plusieurs hôtes (VMs ou serveurs physiques).
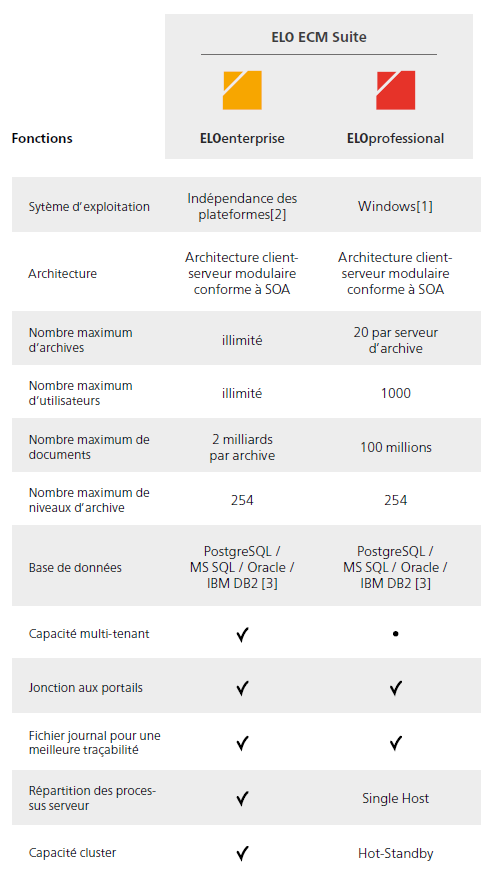
Si vous travaillez avec ELOprofessional, vous pouvez répartir les composants serveur ELO (par exemple ELO Automation Service (ELOas)) sur plusieurs Tomcats, si ceux-ci se trouvent sur un système serveur (VM ou serveur physique). En revanche, en ce qui concerne ELOenterprise, il est possible d'installer les serveurs Tomcat sur plusieurs systèmes serveurs (VM ou serveurs physiques).